[딥러닝] 신경망 개념 이해와 퍼셉트론 실습
신경망(Neural Network)이란?
신경망은 인간의 뇌 구조에서 영감을 받은 기계학습 모델로, 입력 데이터를 받아 여러 층을 거쳐 출력값을 예측하는 구조이다. 특히 이미지, 음성, 자연어, 숫자 등 다양한 데이터를 처리할 수 있고, 요즘 우리가 말하는 딥러닝(Deep Learning)의 가장 기본적인 구성 요소이다.
신경망(Neural Network)이란 여러 개의 연산 노드(=뉴런, neuron)들이 층(Layer)으로 구성되어 있고, 이 노드들이 가중치(weight)와 편향(bias)를 바탕으로 데이터를 처리하는 모델이다.
퍼셉트론(Perceptron)
퍼셉트론은 가장 기본적인 인공 뉴런이며, 입력값들과 각각의 가중치를 곱해서 모두 더한 후, 일정 기준(임계값)을 넘으면 1, 아니면 0을 출력하는 간단한 구조이다. 아래는 OR연산을 하는 퍼셉트론이다.
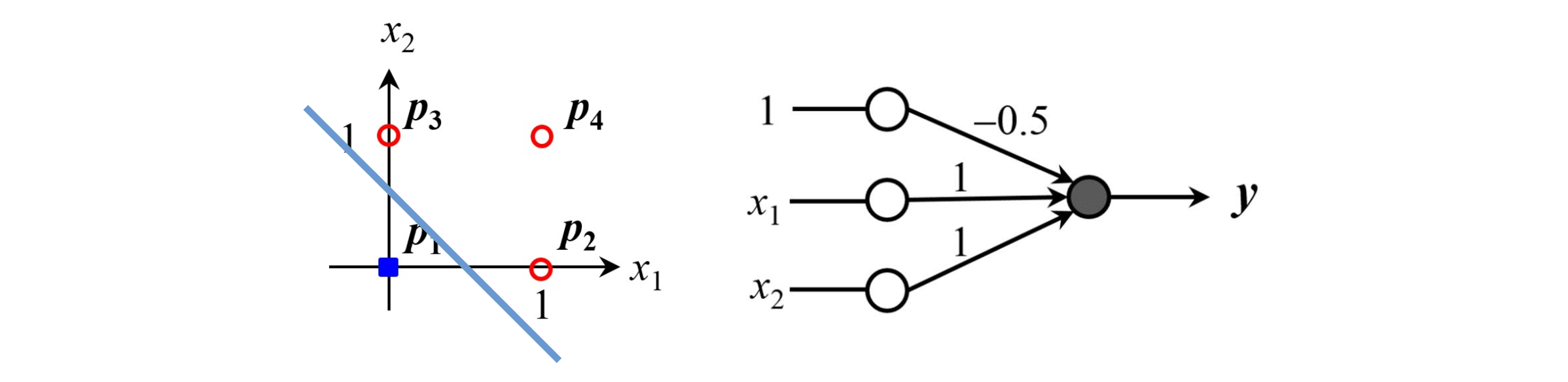
실습
퍼셉트론은 아래 수식을 따른다.
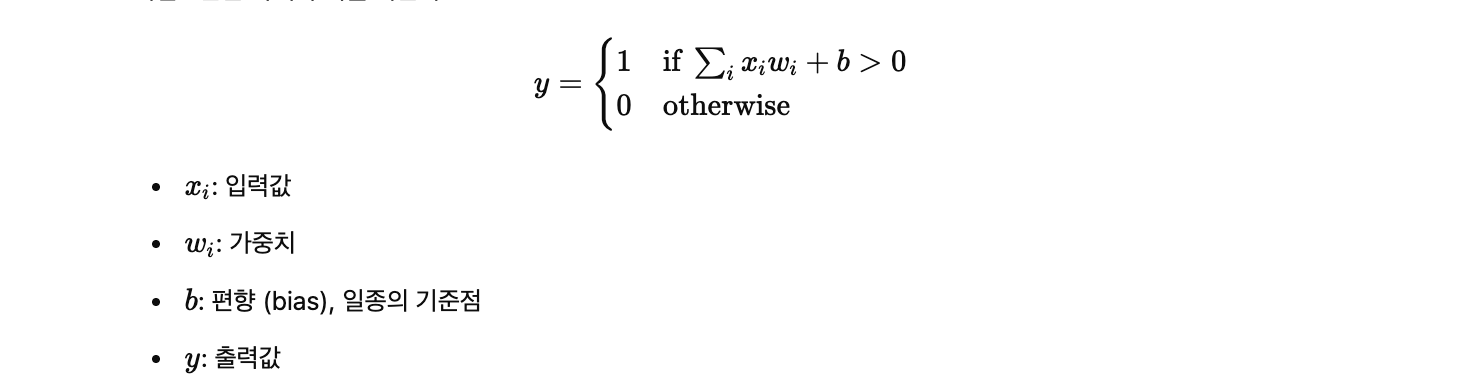
퍼셉트론은 가중치가 적용된 입력의 총합이 일정 기준(bias)보다 크면 1, 아니면 0을 출력한다. 즉 이진 분류기(Binary classification)이다.
step_funtion
def step_function(x):
return 1 if x > 0 else 0
계단 함수라고 불리는 이 함수는 단순히 입력이 0보다 크면 1, 아니면 0을 반환하는 함수이다. 이게 바로 퍼셉트론의 활성화 함수 역할을 한다. 즉, 켜질지(1), 꺼질지(0)를 결정하는 것이다.
perceptron
def perceptron(x, w, b):
weighted_sum = sum(xi * wi for xi, wi in zip(x, w)) + b
return step_function(weighted_sum)
- x : 입력 벡터(예: [1,0])
- w : 가중치 벡터(예: [0.5, 0.5])
-
b : 편향값
- 퍼셉트론 함수의 작동 원리
# 예시 입력
x = [1, 0] # 입력 벡터
w = [0.5, 0.5] # 가중치
b = -0.7 # 편향 (threshold 역할)
output = perceptron(x, w, b)
print("퍼셉트론 출력:", output)
...
weighted_sum = sum(xi * wi for xi, wi in zip(x, w)) + b
...
1. zip(x, w) : 입력과 가중치를 한쌍으로 묶는다.
2. sum(…) : 각각 곱한 뒤 더한다.->1x0.5 + 0x0.5 = 0.5
3. ..+ b : 편향 b = -0.7을 더한다.->0.5 + (-0.7) = -0.2
4. step_funtion()에 넣어서 최종 출력을 계산한다.->step_function(-0.2) → 0
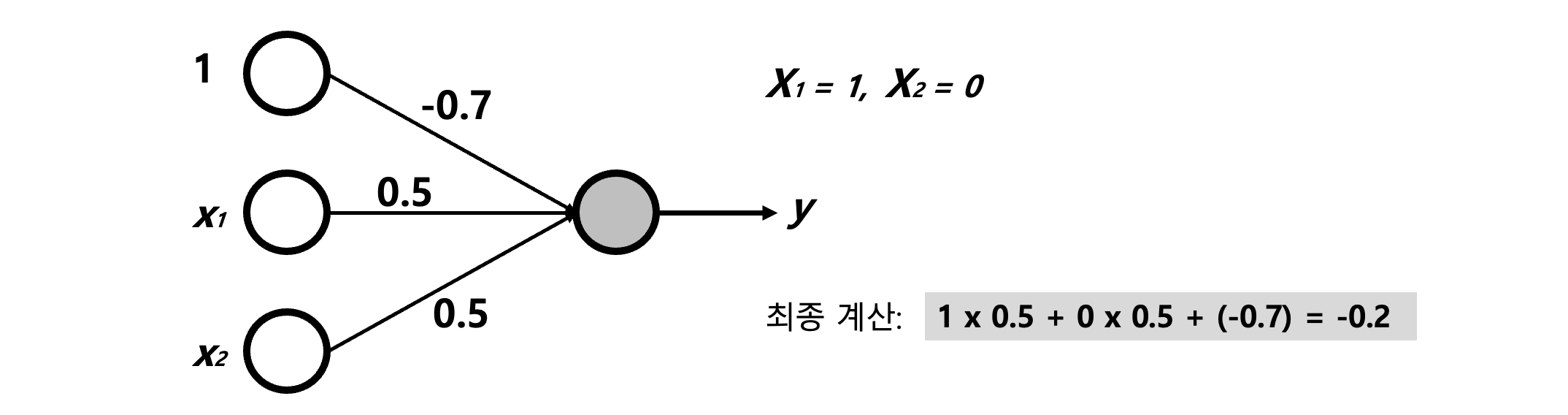
요약
위 코드는 간단히 말해 입력의 합이 기준점(-0.7)을 넘는가? 넘으면 1, 아니면 0 이라는 조건문 판단기라고 생각하면 된다. 만약 입력이 [1, 1]이라면 아래와 같은 결과가 나오게 된다.
1×0.5 + 1×0.5 + (-0.7) = 1.0 - 0.7 = 0.3
step_function(0.3) → 1
즉, 둘 다 1일 때만 활성화되는 AND 게이트처럼 행동한다. 퍼셉트론은 적절한 가중치와 편향 설정만으로 다음도 구현 가능하다.

활성화 함수(Activation Function)
활성화 함수는 퍼셉트론의 출력 결과를 결정하는 함수이다. 선형 함수만 있으면 신경망이 복잡한 문제를 풀 수 없기 때문에, 비선형성을 주기 위해 필요하다. 대표적인 함수들은 아래에 있다.

실습
아래 실습 전체 구조 요약
[입력층] → [은닉층1] → [은닉층2] → [출력층] → softmax(확률 출력)
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def relu(x):
return np.maximum(0, x)
x = np.linspace(-5, 5, 100)
import matplotlib.pyplot as plt
plt.plot(x, sigmoid(x), label="Sigmoid")
plt.plot(x, relu(x), label="ReLU")
plt.axhline(0, color='black', linestyle='--')
plt.axvline(0, color='black', linestyle='--')
plt.title("활성화 함수")
plt.legend()
plt.grid()
plt.show()
다층 퍼셉트론(MLP, Multi-Layer Perceptron)
MLP는 퍼셉트론을 여러 층으로 쌓은 구조이다.
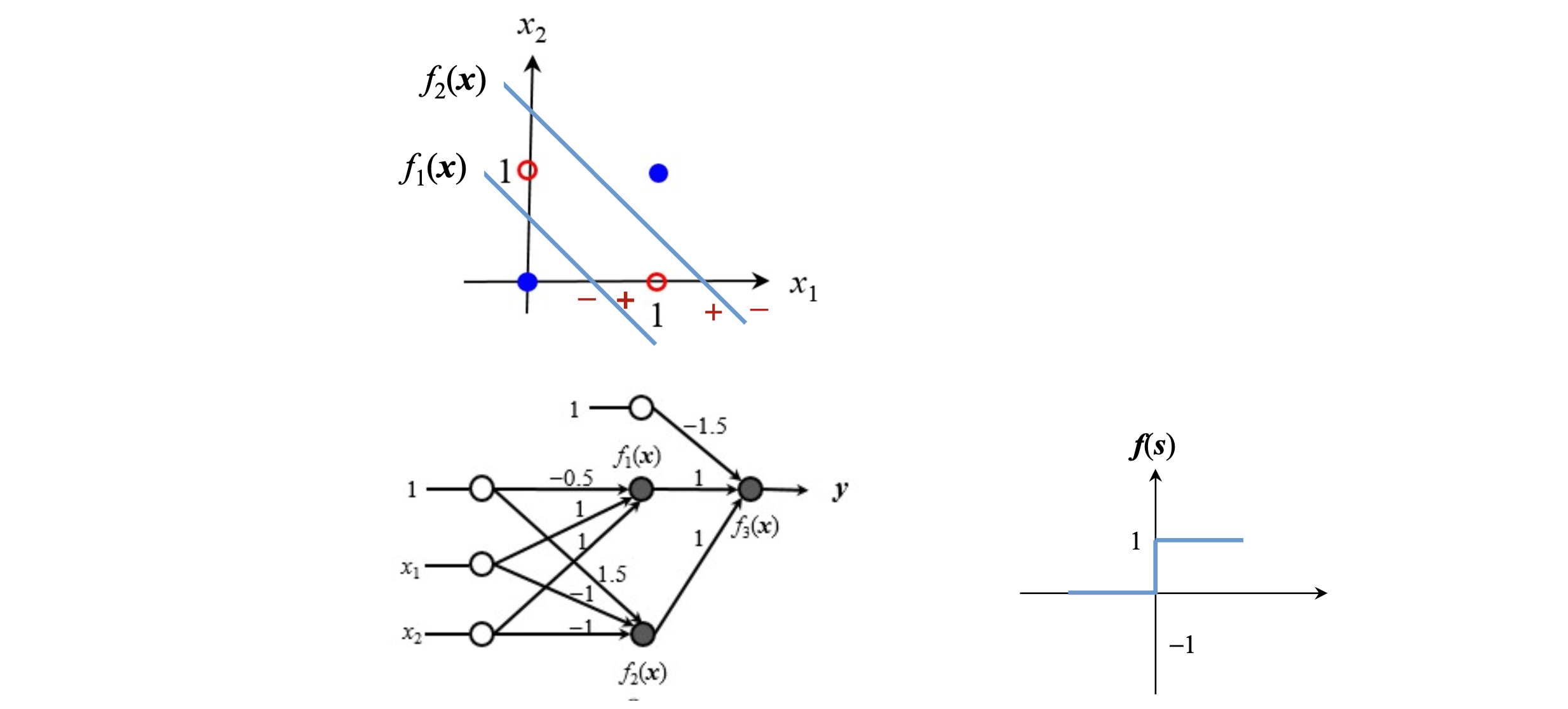
구성은 입력층->은닉층1->은닉층2->…->출력층 으로 구성되어있다. 각 층의 뉴런은 모두 다음 층의 뉴런과 연결되어 있다.(Fully Connected)
실습(Forward Propagation)
아래 다층 퍼셉트론 신경망 실습 코드는 가중치와 편향 값을 임의로 지정하고 forward 연산만 수행하는 코드이다.
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 입력층
x = np.array([1.0, 0.5])
# 첫 번째 은닉층
w1 = np.array([[0.1, 0.3],
[0.2, 0.4]])
b1 = np.array([0.1, 0.2])
a1 = np.dot(x, w1) + b1
z1 = sigmoid(a1)
# 두 번째 은닉층
w2 = np.array([[0.1, 0.4],
[0.2, 0.5]])
b2 = np.array([0.3, 0.1])
a2 = np.dot(z1, w2) + b2
z2 = sigmoid(a2)
# 출력층
w3 = np.array([[0.3, 0.7],
[0.5, 0.2]])
b3 = np.array([0.2, 0.3])
a3 = np.dot(z2, w3) + b3
def softmax(x):
e = np.exp(x - np.max(x))
return e / np.sum(e)
y = softmax(a3)
print("출력 결과 (확률):", y)
시그모이드 함수 정의
def sigmoid(x):
return 1 / (1 + np.exp(-x))
- 비선형 활성화 함수로 입력값이 커질수록 1에 가까워지고, 작아질수록 0에 가까워진다.
- 출력 범위: 0~1
- MLP에서 은닉층에 자주 사용된다.
입력층
x = np.array([1.0, 0.5])
- 입력 벡터 x
- 2개의 값을 가진 입력이다 예를 들어, x[0]=키 x[1]=몸무게
첫 번째 은닉층
w1 = np.array([[0.1, 0.3],
[0.2, 0.4]])
b1 = np.array([0.1, 0.2])
a1 = np.dot(x, w1) + b1
z1 = sigmoid(a1)
- w1 : 2(입력) -> 2(은닉층)으로 가는 가중치(2x2행렬)
- b1 : 은닉층 뉴런 2개에 각각 더해줄 편향
- 수치 계산 예시

두 번째 은닉층
w2 = np.array([[0.1, 0.4],
[0.2, 0.5]])
b2 = np.array([0.3, 0.1])
a2 = np.dot(z1, w2) + b2
z2 = sigmoid(a2)
- z1 -> 은닉층1의 출력 -> 은닉층2로 전달됨
- w2 : 은닉층1(2개) -> 은닉층2(2개)
- b2 : 은닉층2 편향
- 계산 흐름
- a2 = z1 * w2 + b2
- z1은 이전 sigmoid 결과
- 결과는 다시 sigmoid 통과 -> z2
출력층
w3 = np.array([[0.3, 0.7],
[0.5, 0.2]])
b3 = np.array([0.2, 0.3])
a3 = np.dot(z2, w3) + b3
- z2 : 은닉층2의 출력 -> 출력층으로 전달
- w3 : 은닉층2(2개) -> 출력층(2개 클래스 가정)
- b3 : 출력층 편향
- 이 단계에서 아직 softmax는 적용 전이고, a3은 각 클래스에 대한 점수(logits)라고 봐도 된다.
소프트맥스(softmax)
def softmax(x):
e = np.exp(x - np.max(x)) # 오버플로우 방지
return e / np.sum(e)
- 출력층에서 나온 점수들을 확률 분포로 변환
- 모든 클래스의 확률을 더하면 항상 1이 된다.
y = softmax(a3)
print("출력 결과 (확률):", y)
최종 출력 결과 : 예측 확률
y는 예를 들어 아래와 같은 형식으로 나올 수 있다.
출력 결과 (확률): [0.371, 0.629]
- 모델이 두 번째 클래스일 확률이 더 높다고 판단한 것이다.
요약

순전파(Forward propagation)
신경망에서 입력값이 출력으로 전달되는 계산 과정이다. 각 층을 거치면서:
-
- 가중치 곱 + 편향
-
- 활성화 함수 적용 이렇게 반복해 최정 출력값을 만들어낸다. 위 MLP 실습 코드 전체가 forward propagation 과정이다.
손실 함수(Loss function)
모델이 예측한 출력과 실제 정답 사이의 차이를 수치로 나타낸 것이다. 이 수치를 줄이는 방향으로 모델을 학습시킨다.

# Cross Entropy
def cross_entropy(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta))
# 예시
y = np.array([0.2, 0.7, 0.1]) # 모델 예측
t = np.array([0, 1, 0]) # 실제 정답 (2번째 클래스)
loss = cross_entropy(y, t)
print("Cross Entropy Loss:", loss)