[딥러닝] 딥러닝 입문자를 위한 Fashion MNIST 실습
주요 딥러닝 개념 요약
아래는 실습에 필요한 주요 개념들의 요약 정리본이다.
- 신경망(Neural Network) : 인간 뇌의 뉴런 구조를 모방한 계산 모델, 입력 -> 은닉층 -> 출력 구조 로 구성되어 있다.
- 퍼셉트론 : 가장 기본적인 형태의 인공 뉴런으로, 여러 입력을 받아 하나의 출력으로 연결한다.
- Epoch : 전체 데이터셋을 한 번 모두 학습하는 주기로 보통 수십 번 반복한다.
- Batch Size : 한 번에 학습하는 데이터 묶음 크기이다. 예를 들면 128개씩 학습
- Activation Function : 활성화 함수. 비선형성을 추가해 모델의 복잡한 표현력을 향상시킨다.(ReLU, Sigmoid, Softmax 등)
- Loss Function : 손실 함수. 예측 결과와 실제 값 사이의 차이를 수치화한다.(Categorical Crossentropy 등)
- Optimizer : 손실을 줄이기 위해 가중치를 업데이트하는 알고리즘이다.(Adam, SGD 등)
- Dropout : 학습 중 일부 뉴런을 끔으로써 과적합을 방지하는 기법이다.
Fashion MNIST 실습
Tensorflow + Keras + VSCode 환경에서 처음부터 끝까지 실습하며 딥러닝 신경망과 주요 개념을 익히는 실습이다.
Fashion MNIST 신경망은 패션 아이템 이미지를 분류하는 신경망 모델이다.
필요한 라이브러리 불러오기
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# 그래프(정확도 변화)를 그리기 위한 라이브러리
import matplotlib
matplotlib.use("TkAgg") # Macos에서 그래프 창 강제 활성화
import matplotlib.pyplot as plt # 그래프를 그리는 명령어들이 포함됨
- Tensorflow : 구글이 만든 딥러닝 프레임워크로 머신러닝과 딥러닝 모델을 만들고 학습시키는 데 필요한 도구들이 들어있다.
- Keras : Tensorflow 안에 포함된 고수준 딥러닝 라이브러리이다. 복잡한 딥러닝 모델도 몇 줄의 코드로 쉽게 만들 수 있게 도와준다.
- layers : 신경망의 층(레이어)를 구성할 때 사용된다.(예: Dense, Dropout 등)
- matplotlib : 파이썬의 대표적인 그래프 시각화 라이브러리로, 모델 학습 과정을 그래프로 확인하거나 결과를 시각화할 수 있다.
데이터 불러오기
fashion_mnist = keras.datasets.fashion_mnist
# 데이터셋 구성:
# - 28x28 크기의 흑백 이미지 70,000장 (60,000개 학습용 + 10,000개 테스트용)
# - 각 이미지는 티셔츠, 바지, 신발 등 10가지 카테고리 중 하나를 나타냄
- keras.datasets.fashion_mnist : Keras에서 제공하는 Fashion MNIST 데이터셋을 불러오는 객체이다.
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
- load_data() : Fashion MNIST 데이터셋을 학습용과 테스트용으로 나누어 로드하는 함수이다.
- 이 줄의 구조는 파이썬의 튜플 언패킹이다. 즉 데이터를 4개로 나눠 받음을 의미한다.
- train_images : 학습에 사용할 이미지 데이터 60000장(28x28 크기의 흑백 이미지)
- train_labels : 학습용 이미지 각각의 정답(정수형 숫자, 0-9 사이)
- test_images : 테스트용 이미지 데이터 10000장
- test_labels : 테스트 이미지의 정답
- 이미지(images)는 실제 딥러닝 모델이 입력으로 받는 데이터(28x28 숫자 행렬, 픽셀값)이며, 라벨(Labels)은 해당 이미지가 어떤 클래스(카테고리)인지 알려주는 정답을 의미한다. 이렇게 이미지와 정답이 쌍으로 되어 있어야 “학습”이 가능하기 때문에 이미지와 라벨을 분리한다.
데이터 전처리
train_images = train_images.reshape((60000, 28 * 28)).astype("float32") / 255
test_images = test_images.reshape((10000, 28 * 28)).astype("float32")/255
- 원래의 이미지 구조는 60000장의 이미지, 각 이미지 크기는 28x28 픽셀로 구성되어있다. 즉, 총 28 x 28 = 784개의 숫자로 구성된 이미지이다. 그런데 딥러닝에서 사용하는 Dense Layer(완전 연결 신경망)는 1차원 벡터만 입력 받을 수 있다. 그래서 각 2D 이미지(28x28)를 1D 벡터(784길이)로 펼쳐주는 게 reshape((60000, 784))의 의미이다.
- .astype(“float32”) : Python에서는 기본적으로 이미지가 정수 타입(uint8)이다. 하지만 딥러닝에서는 실수(floating point) 형태가 계산에 더 적합하다. 실수는 미세한 값 조정에 유리하며, 대부분의 딥러닝 프레임워크는 float32를 기본으로 사용한다. 또한 float64는 더 정밀하지만 계산이 느리므로 float32가 가장 균형이 좋다.
- 정규화 하는 이유 :
- 데이터 범위를 0-1로 맞추면 학습이 훨씬 안정적이다.
- 신경망은 너무 큰 입력값이 들어오면 제대로 학습이 안 될 수 있다.
- 특히 ReLU, sigmoid, softmax 같은 함수는 작은 수에 민감하게 반응한다.
- 픽셀 값은 0 ~ 255 사이의 정수 값이다. 255는 픽셀의 최댓값이므로, 0 ~ 255 값을 0.0 ~ 1.0 으로 바꾸기 위해 모든 값을 255로 나눈다.
train_labels = keras.utils.to_categorical(train_labels)
test_labels = keras.utils.to_categorical(test_labels)
- keras.utils : keras는 여러 기능을 제공하는 딥러닝 도구이다. utils는 그 중에서도 유용한 함수들(=utilities)을 모아놓은 보조 기능 모음집이다. to_cateforical() 또한 이 안에 있는 함수이다.
- to_categorical() : 정수 라벨 -> one-hot 인코딩된 벡터로 바꿔주는 함수이다. 각 숫자마다 자기 위치만 1, 나머진 0인 벡터로 바꿔준다. 이렇게 바꿔주는 이유는 딥러닝에서 출력층의 확률 벡터(Softmax)와 비교하기 위함이다. 신경망 출력은 확률 벡터 형태인데, 라벨도 같은 형태(벡터)로 맞춰야 손실 계산(categorical_crossentropy)이 가능하기 때문에 one-hot 인코딩이 필요하다.
# one-hot 예시
3 -> [0 0 0 1 0 0 0 0 0 0]
신경망 모델 구성
model = keras.Sequential()
model.add(layers.Dense(256, activation='relu', input_shape=(784,)))
model.add(layers.Dropout(0.3))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
- Sequential() : 이 객체는 층(layer)을 하나씩 순서대로 쌓는 딥러닝 모델을 만들기 위한 툴이다.
입력 -> 은닉층1 -> 은닉층2 -> 출력
- 위와 같은 간단한 구조는 Sequential()로 만들 수 있다.
-
복잡한 구조(CNN, RNN, 여러 경로가 있는 모델)는 나중에 Functional API나 Subclassing으로 만든다.
-
model.add(…) : add()는 이름 그대로 모델에 레이어(층)를 추가하는 함수이다. Sequential() 모델에 순서대로 레이어를 붙이는 방식이다.
-
Dense(…) : Dense는 완전연결층(fully-connected layer)이다. 이전 층의 모든 뉴런이 이층의 모든 뉴런과 연결되는 구조이다.
- 매개변수 설명 :
- 256 : 이 층에 있는 뉴런(노드) 개수
- activation=’relu’ : ReLU 함수 사용 -> 비선형성 추가, 학습 효율 향상
- input_shape=(784,) : 입력 데이터 크기 -> 784개(28x28 이미지를 펼친 벡터)
- 입력층에는 input_shape가 꼭 필요하고, 이후 레이어는 자동으로 다음 크기를 따라간다.
-
Dropout Layer : 학습 중 30% 뉴런을 무작위로 끄는 레이어이다. 너무 잘 외워버린 모델이 오히려 새로운 데이터에서 성능이 떨어지는 걸 막기 위해 사용한다.(과적합 방지)
- Softmax : 각 클래스에 대한 확률(0~1)을 출력해주는 함수이다. -> 가장 높은 확률을 가진 클래스가 예측 결과가 된다.
컴파일
딥러닝 모델의 학습 설정을 하는 핵심 단계이다. 즉, 모델이 어떻게 학습할지, 무엇을 기준으로 평가할지를 정하는 단계이다.
model.compile(optimizer='adam',
loss = 'categorical_crossentropy',
metrics=['accuracy'])
- optimizer : 모델이 어떻게 학습을 진행할지(가중치 업데이트 방법) 즉, 모델이 더 잘 맞게 하려면 어떻게 가중치를 바꿀까?를 결정하는 알고리즘이다.
- adam : adam은 가장 널리 쓰이는 효율적인 최적화 알고리즘이다. 내부적으로는 Momentum + RMSProp 개념을 결합해 학습 속도도 빠르고, 자동으로 학습률을 조절해줘서 편하다.
- 쉽게 말해, 모델이 ‘정답에서 얼마나 벗어났는지’ 보고, ‘다음엔 이쪽으로 조금 조정해야겠다!’라고 판단하는 뇌와 같은 역할을 한다.
- loss : 모델이 얼마나 틀렸는지를 수치로 표현하는 함수(손실 함수)
- categorical_crossentropy는 다중 클래스 분류에 사용하는 대표적인 손실함수이다.
- metrics : 학습 성과를 평가할 지표(보통은 정확도 accuracy 사용)
- accuracy는 예층이 정답과 일치한 비율(정확도)을 의미하며, 일반적으로 분류 문제에서는 accuracy만 있으면 충분하다.
학습(Training)
history = model.fit(train_images, train_labels, epochs=10, batch_size=128, validation_split=0.2)
- epochs=10 : 에폭 수, 전체 데이터를 10번 반복해서 학습한다는 의미이다.
- batch_size=128 : 배치 크기, 한 번에 128개 이미지씩 묶어서 학습한다는 의미이다.
- validation_split=0.2 : 검증용 데이터 분리 비율, 학습 데이터 중 20%는 검증용으로 따로 뺀다는 의미이다.
-
즉, 60000장의 이미지 중 80%인 48000장은 실제 학습에 사용하고, 20%인 12000장은 검증(validation)에 사용한다는 의미이다. 이렇게하면 모델이 진짜 잘 학습되고 있는지 과적합되는 건 아닌지를 실시간으로 확인할 수 있다.
- history : fit() 함수는 학습이 진행되는 동안의 정보를 history 객체에 담아 반환해준다. 즉, history에는 매 에폭마다의 손실/정확도 기록이 저장된다는 의미이다.
테스트 데이터 평가
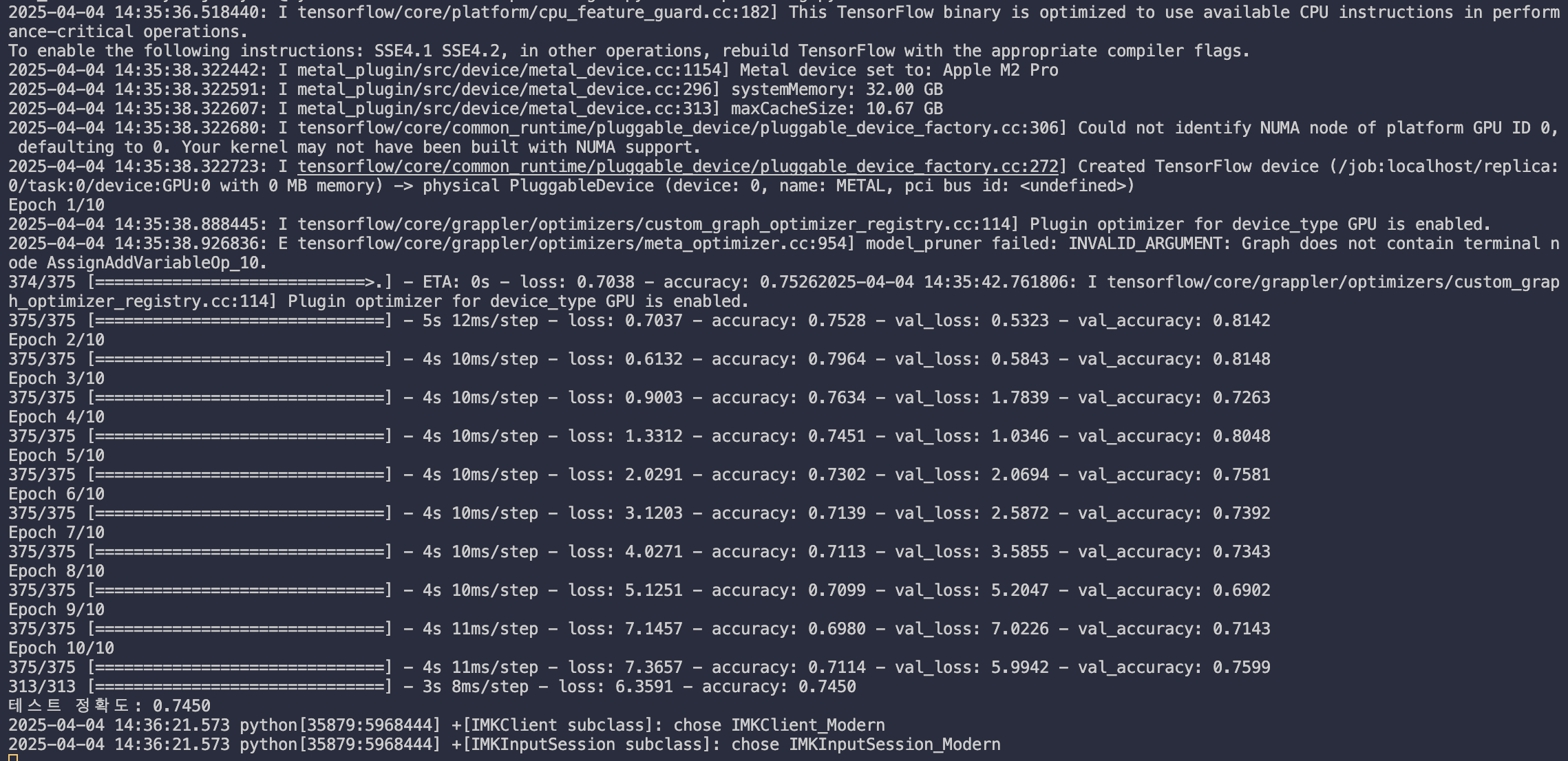
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f'테스트 정확도: {test_acc:.4f}')
- model.evaluate(…) : 학습이 끝난 모델을 테스트 데이터로 평가하는 함수이다. evaluate(x, y) -> 테스트 데이터(x)와 정답(y)을 넣으면 loss(손실값)와 accuracy(정확도)를 반환해준다.
- test_lass : 예측이 얼마나 틀렸는지(낮을수록 좋다.)
-
test_acc : 예측이 얼마나 정확했는지(높을수록 좋다.)
- print(…)
- .4f는 소수점 4자리까지 깔끔하게 출력하겠다는 의미이다. (예: 테스트 정확도 : 0.8735)
학습 정확도 시각화
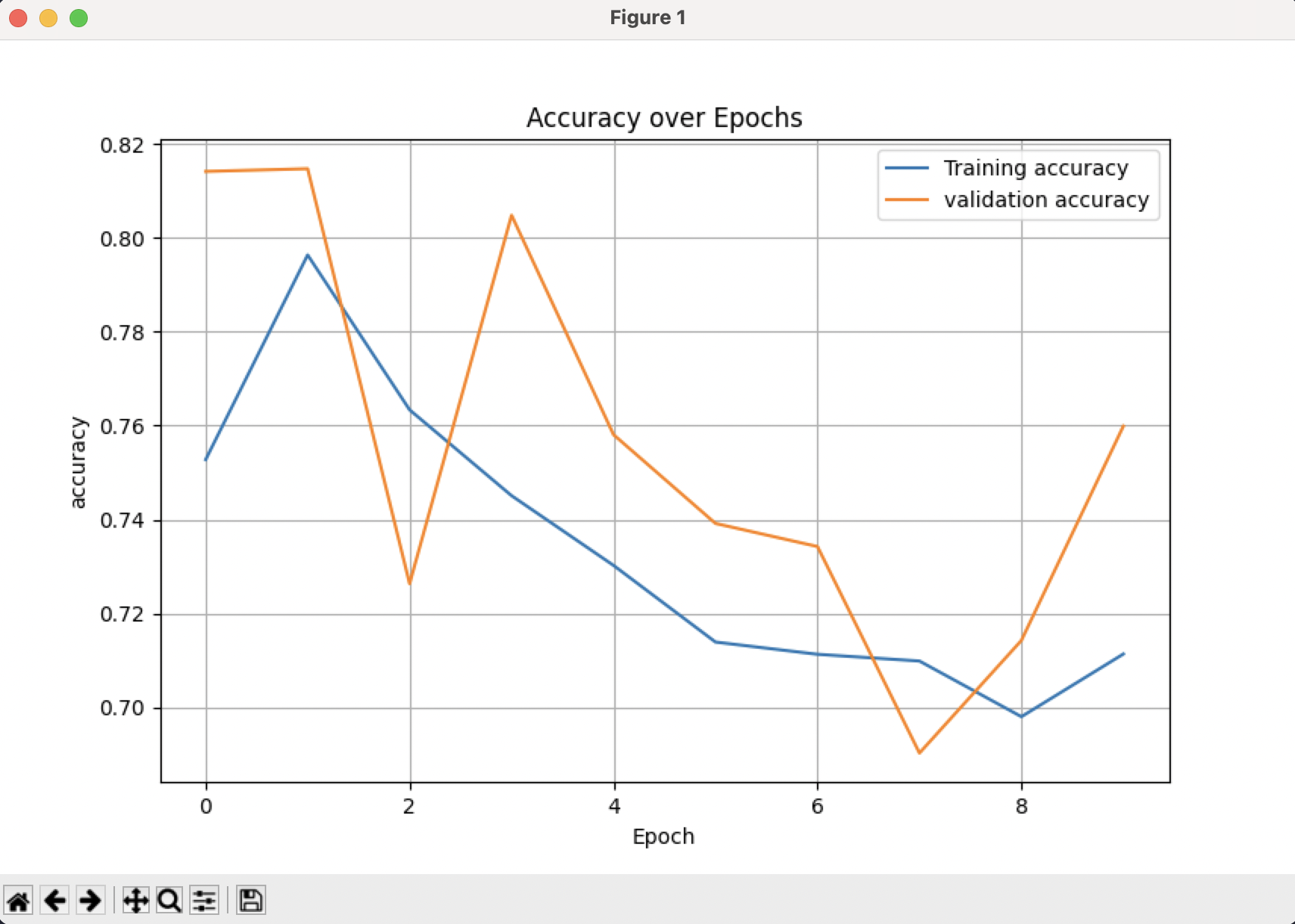
plt.plot(history.history['accuracy'], label='Training accuracy')
plt.plot(history.history['val_accuracy'], label='validation accuracy')
plt.xlabel('Epoch')
plt.ylabel('accuracy')
plt.legend()
plt.title('Accuracy over Epochs')
plt.grid()
plt.show()
- plt.plot(…) : history.history 안에는 학습 과정 중에 기록된 값들이 딕셔너리 형태로 들어있다.
- accuracy는 훈련 데이터에서의 정확도를 의미하며, 이걸 Epock(반복 학습 횟수)에 따라 그래프로 그린다.
- val_accuracy는 검증 데이터에서의 정확도를 의미한다. 학습 중 20%의 데이터를 떼어놓은 검증용 데이터에서의 모델 성능이다. 이걸 같이 그리면 과적합 여부를 알 수 있다.
- plt.xlabel(…) : x축 Epoch(학습 반복 횟수) / y축 정확도(0-1 사이 값)
- plt.title(…) : 그래프 제목 설정
- plt.legend() : 그래프에 표시된 두 선을 설명하는 범례를 표시
- plt.grid()/plt.show() : grid() : 눈금선 추가 -> 더 보기 쉽다. / show() : 그래프 창 띄우기(쓰지않으면 안보일 수도 있다.)
전체 코드
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib
matplotlib.use("TkAgg") # Macos에서 그래프 창 강제 활성화
import matplotlib.pyplot as plt
matplotlib.use("TkAgg") # Macos에서 그래프 창 강제 활성화
# tensorflow 와 keras : 딥러닝 모델 구성, 학습, 평가에 필요한 모든 기능을 제공
# layers : 신경망의 각 층(Dense, Dropout 등)을 만드릭 위한 모듈
# matplotlib.pyplot : 결과 시각화(학습 정확도 그래프 등)
# 데이터 불러오기
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
# fashion_mnist : Keras 내장 데이터 셋(28x28 흑백 의류 이미지 10종)
# (train_images, train_labels) : 훈련용 이미지/라벨
# (test_images, test_labels) : 테스트용 이미지/라벨
# 데이터 전처리
train_images = train_images.reshape((60000, 28 * 28)).astype("float32") / 255
test_images = test_images.reshape((10000, 28 * 28)).astype("float32")/255
# reshape((60000, 28*28)) : 2차원 이미지를 1차원 벡터(784차원)로 변환(Dense Layer 사용을 위해서)
# .astype("float32") : 숫자 타입을 float으로 변환(계산 효율성)
# / 255 : 픽셀 값 정규화
train_labels = keras.utils.to_categorical(train_labels)
test_labels = keras.utils.to_categorical(test_labels)
# to_categorical : 정수형 라벨(0-9)을 one-hot 인코딩 벡터로 변환
# 예 : 3 -> [0 0 0 1 0 0 0 0 0 0]
# 신경망 모델 구성
model = keras.Sequential()
# Sequential() : 층을 순차적으로 쌓는 신경망 구조 선언
model.add(layers.Dense(256, activation='relu', input_shape=(784,)))
# Dense : 완젼 연결층(fully connected layer)
# 256개 노드, ReLu 활성화 함수 사용
# 입력은 784차원 (28x28 이미지 펼친 벡터)
model.add(layers.Dropout(0.3))
# Dropout : 과적합 방지를 위한 기법
# 학습 중 30%의 뉴런을 무작위로 꺼서 일반화 성능 향상
model.add(layers.Dense(128, activation='relu'))
# 또 다른 은닉층 : 노드 수를 128로 줄여서 정보 압축
model.add(layers.Dense(10, activation='softmax'))
# 출력층: 클래스 수 = 10
# softmax : 각 클래스에 대한 확률 출력
# 컴파일
model.compile(optimizer='adam',
loss = 'categorical_crossentropy',
metrics=['accuracy'])
# adam : 효율적인 최적화 알고리즘(SGD 개선 버전)
# categorical_crossentropy : 다중 클래스 분류용 손실 함수
# accuracy : 평가 지표(정확도)
# 학습(Training)
history = model.fit(train_images, train_labels, epochs=10, batch_size=128, validation_split=0.2)
# fit() : 실제 모델 학습
# epochs=10 : 전체 데이터셋을 10번 반복 학습
# batch_size=128 : 128씩 묶어서 학습
# validation_split=0.2 : 훈련 데이터의 20%를 검증용 사용
# history에는 각 에폭마다의 손실과 정확도가 저장된다.
# 테스트 데이터 평가
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f'테스트 정확도: {test_acc:.4f}')
# evaluate : 테스트 데이터에 대해 정확도 및 손실 평가
# 실제 성능 확인용
# 학습 정확도 시각화(옵션)
plt.plot(history.history['accuracy'], label='Training accuracy')
plt.plot(history.history['val_accuracy'], label='validation accuracy')
plt.xlabel('Epoch')
plt.ylabel('accuracy')
plt.legend()
plt.title('Accuracy over Epochs')
plt.grid()
plt.show()
실행 결과