[컴퓨터 비전] 컴퓨터 비전과 영상의 이해
컴퓨터 비전 개요
컴퓨터 비전은 정지 영상이나 동영상으로부터 의미 있는 정보를 추출하는 방법을 연구하는 학문이다. 이는 사람이 눈으로 사물을 보고 인지하는 과정을 컴퓨터가 수행할 수 있도록 구현하는 것을 목표로 한다. 즉, 사람의 눈 역할을 카메라가 대신하고, 사람의 뇌 역할을 컴퓨터가 수학적 알고리즘을 통해 수행하도록 만드는 것이다.
사람이 사물을 보고 인지하는 것은 매우 직관적이고 쉬운 작업이지만, 이를 컴퓨터로 구현하는 일은 복합하다. 전통적인 컴퓨터 비전 방법론에서는 영상을 분석해 유용한 정보를 추출하고, 이를 조합하여 결과를 유추하는 방식으로 문제를 해결한다.
예를 들어, 아래 사진과 같이 빨간새 사과 사진을 컴퓨터에 입력으로 주고, 이 사진의 객체를 사과라고 인식하는 문제에 대해 생각해보자. 흰 배경을 제외한 가운데 영역에 빨간색 성분이 많이 있고 둥근 윤곽을 가지고 있으면 사과라고 인식하게끔 프로그램을 만들면 빨간 사과를 인식할 수 있을 것이다. 그러나 초록색 사과도 함께 인색해야 한다면 사과의 색상 정보에 초록색도 추가해야한다. 만약 토마토가 입력으로 들어오면 상황은 좀 더 복잡해진다. 빨간색 색상 정보와 둥근 윤곽선 정보만으로는 사과와 토마토가 구분이 되지 않으므로 꼭지의 모양까지 고려해야한다. 마지막 사진처럼 배경이 단순하지 않고, 여러 과일이 겹쳐있는 경우에는 인식이 더욱 어려워진다.

컴퓨터 비전에서 주로 활용하는 영상 정보는 밝기, 색상, 모양, 텍스처(texture) 등이 있으며, 이 정보와 머신 러닝 알고리즘을 함께 사용하여 사물을 인지할 수 있다. 그러나 영상으로부터 유용한 정보를 추출하는 것은 쉬운 일이 아니다. 예를 들어, 배경과 객체를 어떻게 구분해야하는지, 빨간색을 판단하기 위해 어떤 수식을 사용해야 하는지, 둥근 윤곽인지 아닌지를 검사하기 위해 어떤 알고리즘이 적합한지 결정하기가 쉽지 않다. 사과와 토마토를 구분하기 위해 꼭지의 모양을 비교하고 싶은데, 꼭지 부분을 찾는 것이 새로운 문제가 되어 버리기도 한다. 게다가 날씨 또는 시간대에 따른 조명 변화, 카메라 시점 변화, 잡음 등의 영향으로 영상의 구성이 일관되지 않는 경우도 많다. 이처럼 영상 데이터에는 다양한 변형이 가해질 수 있기 때문에 영상을 제대로 분석하고 이해하기 위해서는 여러 방식으로 추출한 영상 정보를 복합적으로 사용해야 한다. 그러므로 컴퓨터 비전에서는 영상으로부터 유용한 정보를 추출하는 방법과 추출된 정보를 효과적으로 사용하는 방법을 모두 다루고 있다.
영상의 구조와 표현 방법
영상의 획득과 표현 방법
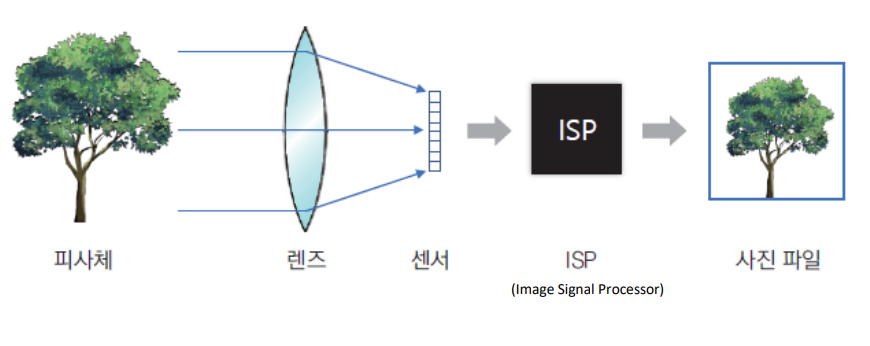
디지털 카메라에서 영상 획득 과정
- 태양의 가시광선 또는 특정 광원에서 발생한 빛이 피사체에 부딪혀 반사되고, 그 반사된 빛이 카마레 렌즈를 통해 카메라 내부로 들어오게 된다.
- 렌즈는 카메라 바깥으로부터 들어온 빛을 굴절시켜 이미지 센서(image sensor)로 모아 주는 역할을 한다.
- 이미지 센서 : 빛을 전기적 신호로 변환하는 포토 다이오드가 2차원 평면상에 배열 되어 있는 장치
- 렌즈에서 모인 빛이 이미지 센서에 닿으면 이미지 센서에 포함된 포토 다이오드가 빛을 전기적 신호로 변환한다.
- 빛을 많이 받은 포토 다이오드는 큰 신호를 생성하고, 빛을 적게 받은 포토 다이오드는 작은 크기의 신호를 생성함으로써 명암이 있는 2차원 영상을 구성한다.
- 포토 다이오드에서 생성된 전기적 신호는 아날로그-디지털 변환기(ADC)를 거쳐 디지털 신호로 바뀐다.
- 디지털 신호는 다시 카메라의 ISP(Image Signal Processor) 장치로 전달된다.
- ISP : ISP 장치는 화이트 밸런스 조정, 색 보정, 잡음 제거 등의 기본적인 처리를 수행한 후 2차원 디지털 영상을 생성한다.
- 이렇게 구성된 영상은 곧바로 컴퓨터로 전송되거나 JPG, TIFF 등의 영상 파일 형식으로 변환되어 저장된다.
디지털 영상의 표현
- 픽셀(Pixel) : 영상을 구성하는 최소 단위 (== 화소)
- 하나의 픽셀은 하나의 밝기 또는 색상을 표현하며, 이러한 픽셀이 모여서 2차원 영상을 구성한다.
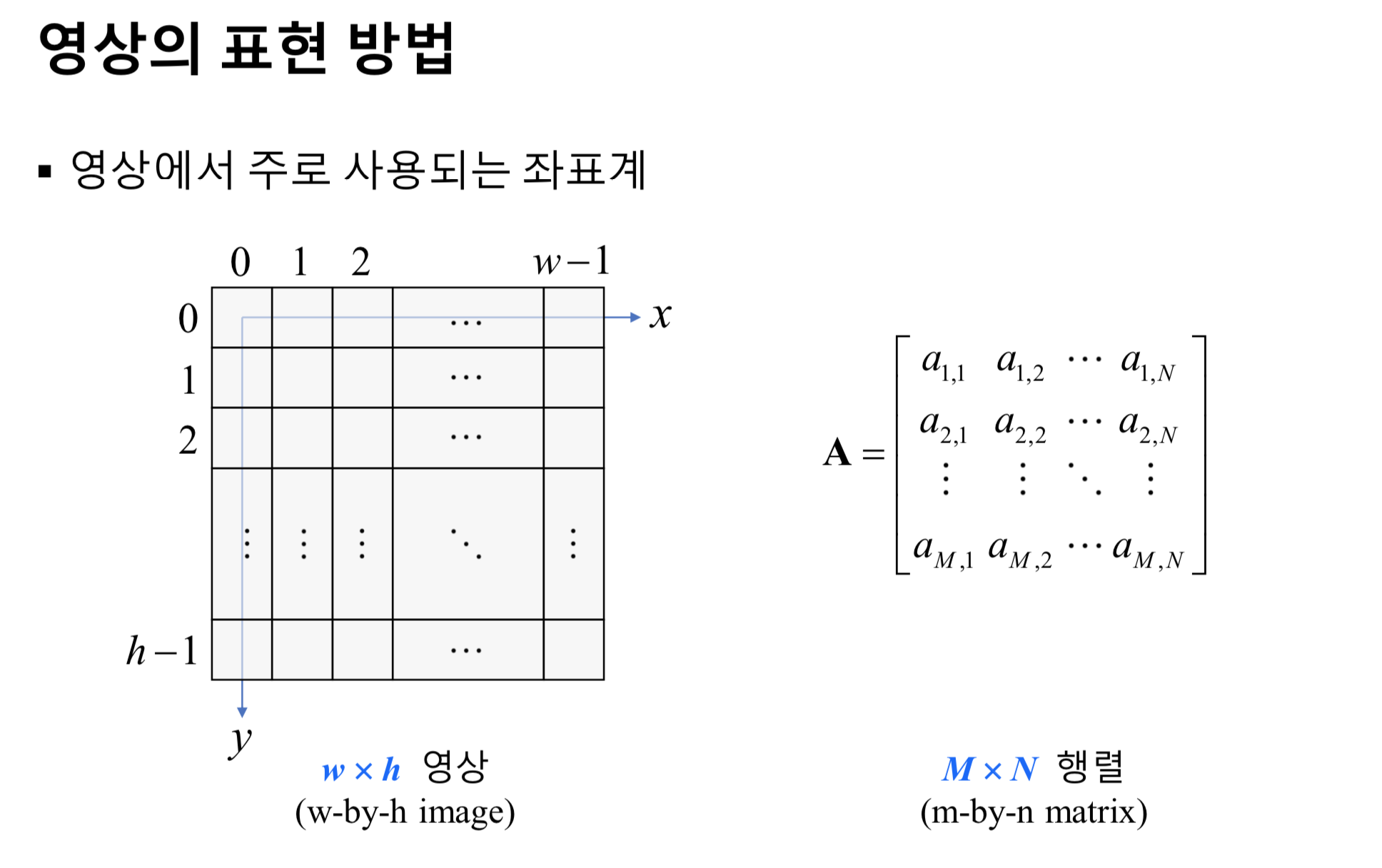
- 영상은 픽셀이 바둑판 처럼 균일한 격자 형태로 배열되어 있는 형태로 표현된다.
- 영상을 표현하는 2차원 xy 좌표계에서 x좌표는 왼쪽에서 오른쪽으로 증가하고, y좌표는 위에서 아래로 증가한다. 위 그림은 가로 크기가 w이고, 세로 크기가 h인 영상이다.
- 이 영상의 픽셀 좌표를 (x,y)로 표현할 경우, x는 0부터 w-1 사이의 정수를 갖고, y는 0부터 h-1 사이의 정수를 갖는다.(좌표를 0부터 표현하는 방식을 0-기반(zero-based) 표현이라 부른다.)
- 영상을 수식으로 표현할 때에는 보통 함수의 형태를 사용한다. 즉, 행렬로 표현
그레이스케일 영상(Grayscale Image)
구조 : 픽셀 값이 단일 채널로 구성되어 있으며, 각 픽셀은 밝기를 나타낸다.
픽셀 값의 표현
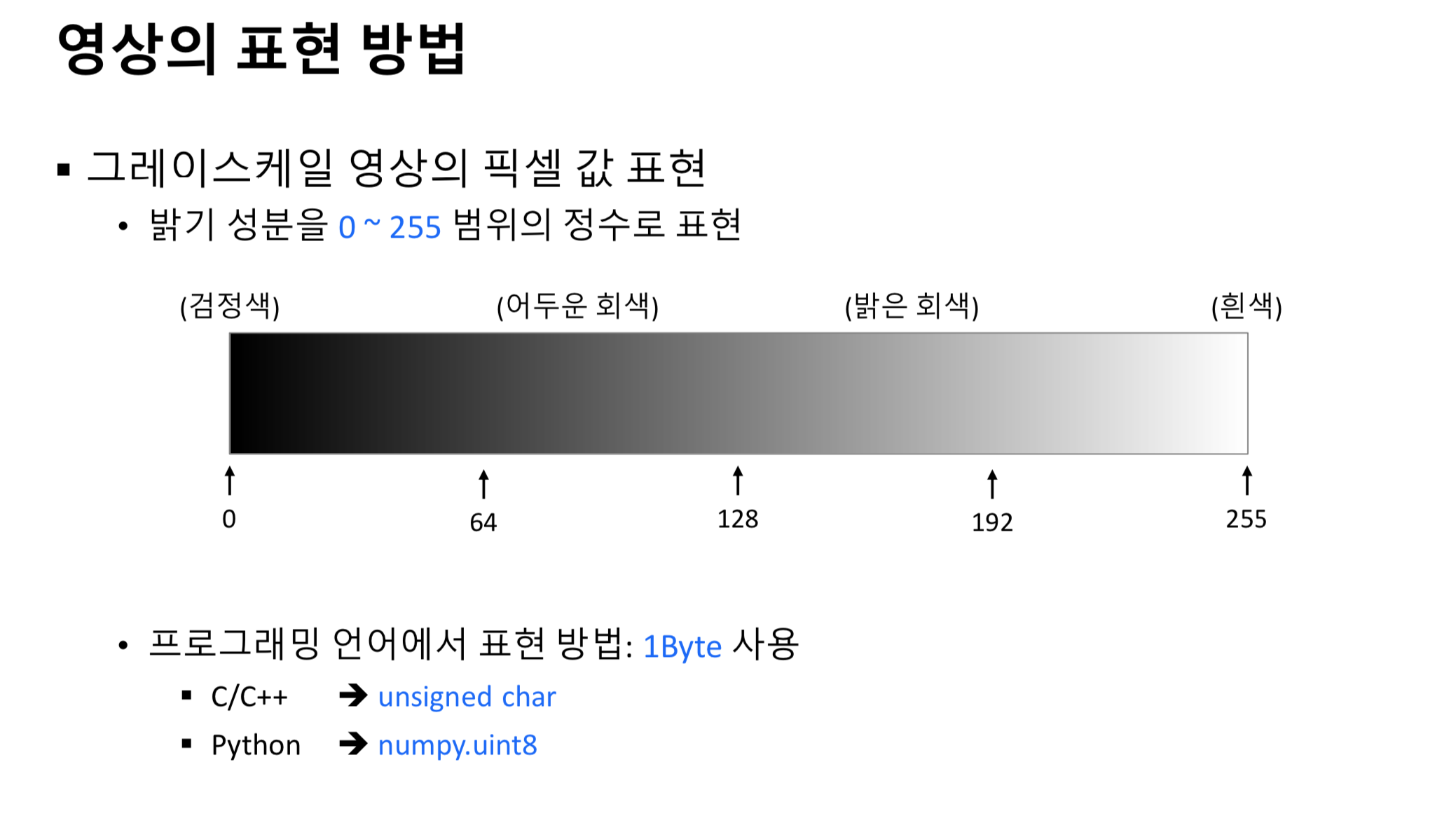
- 일반적으로 0에서 255사이의 값으로 표현된다.
- 0 : 완전한 검은색
- 255 : 완전한 흰색
- 중간값 : 회색의 다양한 명도 수준
특징 : 단순한 구조 덕분에 처리 속도가 빠르고, 많은 컴퓨터 비전 알고리즘에서 기본적으로 사용된다.
- C/C++ 에서는 보통 unsigned char 자료형을 사용한다.
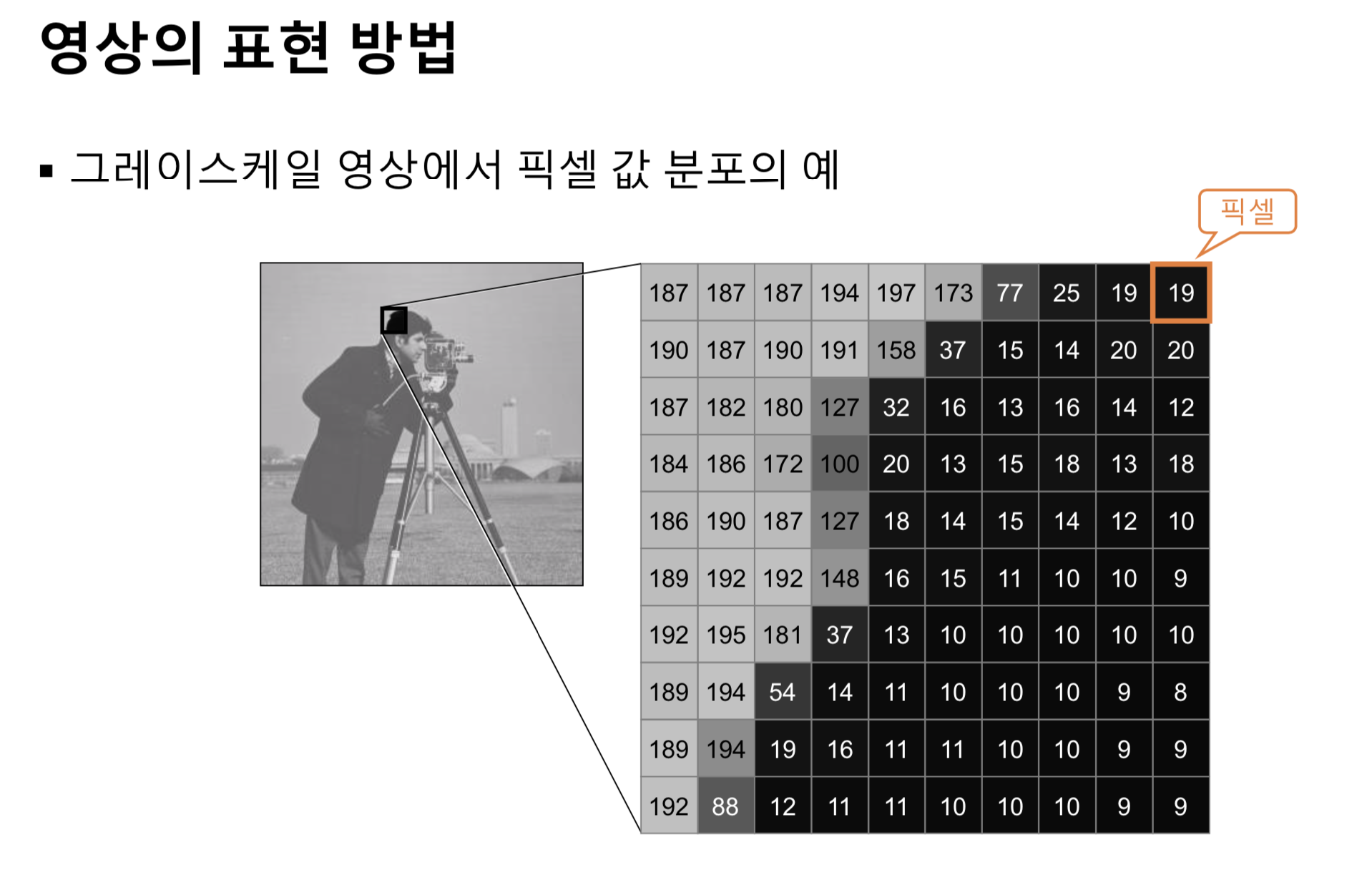
- 아래 그림으로 픽셀 밝기와 그레이스케이 값과의 상관관계를 살펴보면, 영상에서의 밝은 영역의 픽셀은 큰 그레이스케일 값을 가지고, 어두운 영역의 픽셀은 상대적으로 작은 그레이스케일 값을 갖는 것을 알 수 있다.
컬러 영상(Color Image)
구조 : 픽셀 값이 RGB(RED, GREEN, BLUE)로 구성된 3개의 채널로 이루어진다.
- 각 채널은 특정 색상 성분의 강도를 나타낸다.
픽셀 값의 표현
- 각 채널은 0에서 255 사이의 값을 갖는다.

특징 : 컬러 정보가 포함되어 있어 보다 복잡한 객체 탐지, 분류 작업에 유용하다.