[OS] 파일 시스템 - File Systems
Introduction
현대의 컴퓨터 시스템에서 파일 시스템(file system)은 저장 장치 위에 있는 데이터를 체계적으로 관리하고 접근할 수 있도록 도와주는 핵심적인 소프트웨어 계층이다. 사용자와 운영체제 사이에서 데이터를 어떻게 저장하고, 읽고, 수정하며, 삭제할지를 결정짓는 역할을 맡는다
디스크의 기본 특성 : 디스크는 우리가 데이터를 저장하고 꺼내는 데 사용하는 대표적인 비휘발성 저장 장치다. 디스크의 중요한 특성 두 가지를 살펴보자.
첫째, 디스크는 데이터를 덮어쓰는 방식으로 수정할 수 있다(rewrite-in-place). 다시 말해, 특정 위치의 데이터를 삭제하고 그 자리에 새로운 데이터를 저장하는 것이 가능하다. 이는 테이프와 같은 순차 저장 장치와는 구별되는 중요한 특징이다.
둘째, 디스크는 원하는 정보가 저장된 섹터(sector)를 직접 접근(direct access)할 수 있다. 즉, 데이터를 처음부터 차례대로 읽어야 하는 방식이 아니라, 원하는 위치의 섹터를 바로 읽을 수 있어 빠른 접근이 가능하다.
블록(Block) 단위 : 디스크와 메모리 사이에서 데이터를 주고받을 때는 블록(block)이라는 단위가 사용된다. 블록은 보통 여러 개의 섹터로 구성되며, 하나의 섹터는 일반적으로 512바이트 크기를 가진다. 파일 시스템은 데이터를 이 블록 단위로 읽고 쓰기 때문에, 블록 크기는 파일 시스템의 성능에 직접적인 영향을 미친다.
디스크에서 데이터에 접근하는 방식 : 사용자가 디스크에서 원하는 정보를 찾기 위해 각 섹터 번호와 데이터의 크기를 일일이 기억하거나 기록해야 한다면, 이는 매우 비효율적이고 실용적이지 않다. 이를 해결하기 위해 운영체제는 파일 시스템을 통해 데이터를 저장, 검색, 그리고 읽을 수 있는 추상화된 방법을 제공한다. 즉, 사용자는 파일 이름만 알고 있으면 되고, 파일 시스템이 그에 해당하는 데이터의 위치와 크기 등을 알아서 관리해준다.
이와 같은 기능 덕분에, 우리는 ‘파일’이라는 단위로 쉽게 데이터를 다룰 수 있으며, 실제로 물리 디스크 내부에서 어떤 블록에 저장되어 있는지는 알 필요가 없어진다.
System Calls for File Operations
파일 시스템은 단순히 데이터를 저장하는 공간만이 아니다. 사용자와 운영체제 간의 인터페이스 역할을 하며, 사용자가 파일을 다룰 수 있도록 다양한 시스템 콜(system call)을 제공한다. 시스템 콜은 사용자 프로그램이 운영체제의 기능을 사용할 수 있도록 연결해주는 통로라고 할 수 있다.
계층 구조로 본 파일 접근 과정
파일을 읽고 쓰기 위해 사용되는 함수들은 여러 계층으로 구성되어 있다. 아래는 그 구조를 간단히 요약한 것이다.
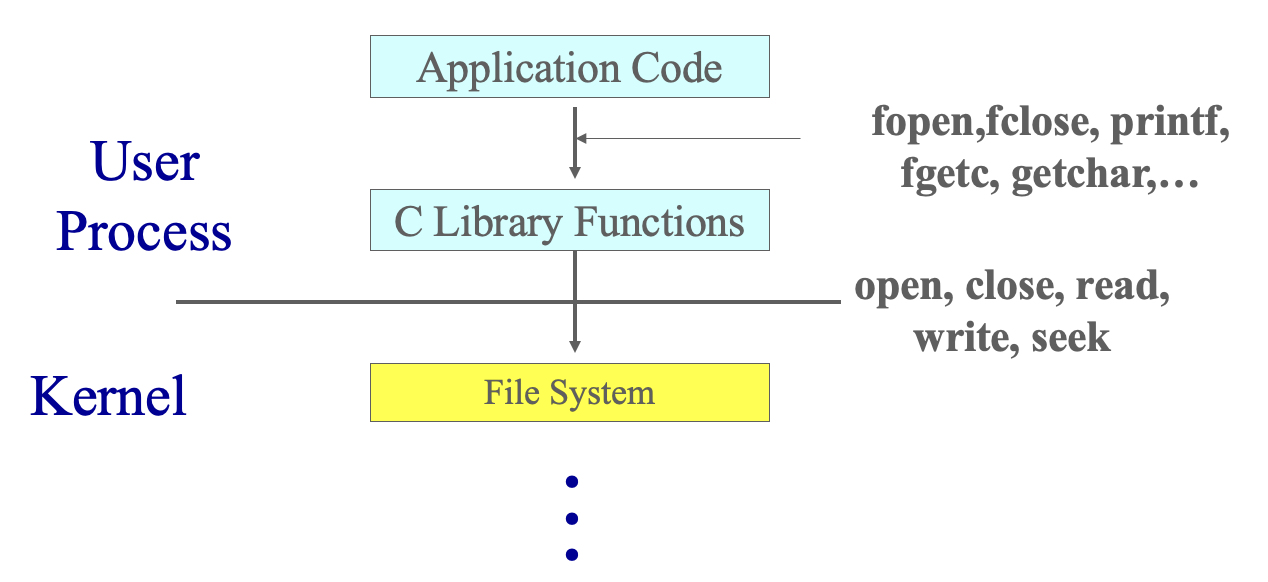
- Application Code(사용자 코드) : 사용자는 printf(), fopen(), getchar() 등과 같은 C표준 라이브러리 함수를 사용한다. 이들은 실제 파일 입출력을 위한 고수준 함수들이다.
- C Library Funtions(C 라이브러리 계층) : fopen() 같은 함수는 내부적으로 운영체제의 시스템 콜인 open() 등을 호출한다. 라이브러리 함수는 사용자 친화적인 인터페이스를 제공하지만, 결국은 시스템 콜을 통해 커널에 요청을 전달한다.
- Kernel(커널 계층) : open(), read(), write(), close(), seek() 등과 같은 시스템 콜은 커널에 직접적인 작업을 요청한다. 커널은 파일 디스크립터를 생성하고, 파일에 대한 정보(위치, 권한, 크기 등)를 관리하며, 디스크로부터 데이터를 읽거나 쓴다.
- File System(파일 시스템 계층) : 커널은 실제 디스크에 접근할 수 없기 때문에, 파일 시스템이 하드웨어 수준의 작업을 대신 수행한다. 파일의 경로를 탐색하고, 불륵을 읽거나 쓰며, 파일 정보를 구성하는 역할을 한다.
이러한 계층 구조는 다양한 종류의 파일 시스템이 존재하더라도, 사용자에게는 일관된 인터페이스를 제공할 수 있게 한다. 사용자는 FAT, NTFS, ext4 등 어떤 파일 시스템이 쓰이든 신경 쓰지 않고, fopen()과 같은 함수만 알고 있으면 된다.
시스템 콜?
시스템 콜은 단순한 함수 호출이 아니다. 사용자 모드(user mode)에서 동작하던 프로그램이 커널 모드(kernel mode)로 전환되어야만 운영체제의 리소스에 접근할 수 있다. 파일 시스템은 커널이 관리하는 대표적인 리소스이므로, 파일 입출력은 시스템 콜을 통해야만 가능하다.
File Descriptor and File Identity
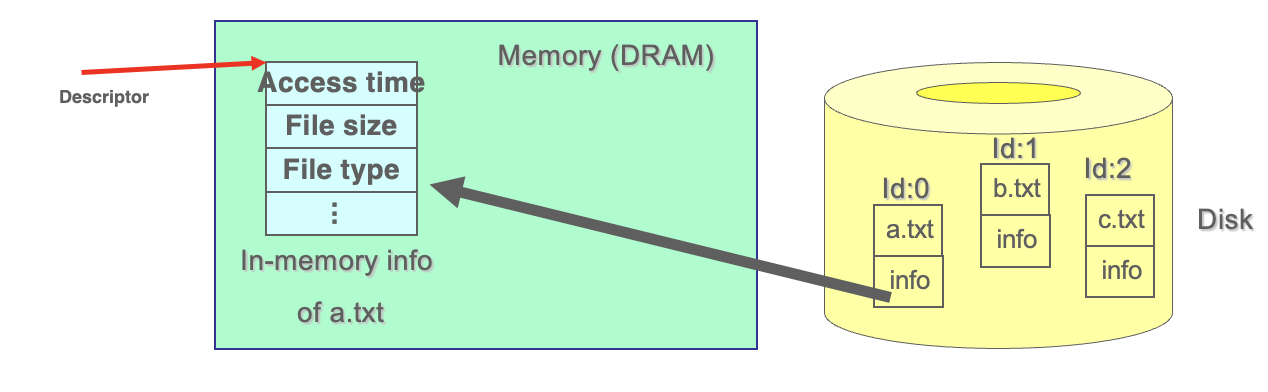
파일 시스템은 사용자가 ‘파일 이름’으로 파일을 식별하도록 해주지만, 운영체제 내부에서는 전혀 다른 방식으로 파일을 식별한다. 커널은 파일을 효율적으로 추적하고 관리하기 위해 ‘파일의 고유한 정체성’을 부여하는데, 여기서 등장하는 개념이 바로 파일 아이디(file identity)와 파일 디스크립터(file descriptor)다.
파일 아이디(File Identity)
파일 아이디는 커널이 파일을 구분하기 위해 사용하는 내부 식별자이다. 사용자는 “data.txt” 같은 이름을 통해 파일에 접근하지만, 운영체제는 해당 파일의 이름을 직접 저장하거나 기억하지 않는다. 대신, 파일이 저장된 디스크 상의 정보(메타데이터)를 추적하는 데 파일 아이디를 사용한다.
UNIX나 Linux 시스템에서는 이 파일 아이디가 inode 번호(inode number)로 구현된다. inode(아이노드)는 디스크에 저장된 파일의 구조와 정보를 설명하는 데이터 블록이다. 이 블록 안에는 파일 크기, 권한, 소유자, 생성 시간, 데이터 블록 위치 정보 등이 저장되어 있으며, 파일 이름은 저장되지 않는다.
즉, 파일 이름은 디렉터리 항목 안에만 존재하고, 실제 파일 자체는 inode 번호로 식별된다.
파일 디스크립터(File Descriptor)
파일 디스크립터는 프로세스가 실행 중에 파일을 열었을 때 커널이 반환하는 정수형 핸들(handle)이다. 이 정수값은 열린 파일을 추적할 수 있는 키처럼 사용되며, 모든 파일 입출력 작업은 이 디스크립터를 통해 이루어진다.
파일 디스크립터는 운영체제가 파일과 관련된 세부 정보를 저장하는 메모리 구조체에 대한 포인터 역할을 한다. 이 구조체에는 다음과 같은 정보가 들어있다:
- 파일 오프셋(파일을 읽거나 쓸 때 현재 위치)
- 접근 모드(읽기, 쓰기, 읽기 + 쓰기 등)
- 참조 횟수(파일을 공유하는 프로세스 수)
- 파일의 inode 정보에 대한 포인터
간단히 말하면,
- 파일 아이디 -> 디스크에 저장된 파일 고유 정보
- 파일 디스크립터 -> 프로세스 실행 중 열려 있는 파일에 대한 핸들
예를 들어, 사용자가 프로그램 내에서 아래와 같은 코드를 작성했다고 가정해보자.
int fd1, fd2;
fd1 = open("/home/park/a.txt", O_RDONLY);
fd2 = open("/home/park/b.txt", O_RDONLY);
이 경우, 운영체제는 다음과 같은 방식으로 동작한다.
- a.txt 파일에 대해 하나의 inode가 존재하고, fd1은 해당 파일에 대한 디스크립터이다.
- b.txt 파일도 inode를 가지며, fd2가 그 핸들 역할을 한다.
- 이 디스크립터들은 각 프로세스의 디스크립터 테이블(descriptor table)에 저장된다.
이 구조는 동일한 파일을 여러 프로세스에서 공유하거나, 여러 번 열었을 때도 커널이 파일 접근을 정확히 관리할 수 있게 해준다.
How the Unix Kernel Represents Open Files - File 오픈 과정
우리는 파일을 열고, 읽고, 쓰고, 닫는 일을 아주 손쉽게 해내지만, 운영체제 내부에서는 이러한 동작을 매우 체계적이고 정교한 구조를 통해 수행하고 있다. UNIX 계열 운영체제에서는 열린 파일 하나하나가 다양한 테이블과 포인터를 통해 추적되고 관리된다. 이 구조를 이해하면 파일 시스템 내부 동작과 성능, 자원 관리까지 더 깊이 있게 이해할 수 있다.
프로세스와 파일 디스크립터 테이블
각 프로세스는 자신만의 파일 디스크립터 테이블(file descriptor table)을 갖고 있다. 이 테이블은 배열 형태로 되어 있으며, 각 인덱스는 해당 프로세스가 열고 있는 파일을 나타낸다. 배열의 각 항목은 우리가 흔히 사용하는 fd 값(예: 0, 1, 2)이 된다.
open() 시스템 콜을 통해 파일을 열면, 커널은 사용 가능한 인덱스 번호를 찾아서 디스크립터를 반환한다. 이 번호는 사용자 코드에서 파일을 참조할 때 쓰이게 된다.
오픈 파일 테이블(Open File Table)
파일 디스크립터 테이블의 각 항목은 오픈 파일 테이블(open file table)의 엔트리를 참조한다. 이 오픈 파일 테이블은 커널 전체에서 공유되는 전역 구조체이며, 열린 모든 파일에 대한 정보를 저장한다. 중요한 점은 동일한 파일을 여러 프로세스가 열더라도 오픈 파일 테이블의 엔트리는 공유될 수 있다는 것이다.
오픈 파일 테이블의 각 엔트리는 다음 정보를 포함한다.
- 파일 위치(File Offset) : 현재 읽기/쓰기 위치
- 참조 카운트(Reference Count) : 이 파일을 참조 중인 디스크립터 수
- 파일 정보 구조체에 대한 포인터 : vnode 또는 inode 등
예를 들어, 두 개의 프로세스가 동일한 파일을 열었을 때, 각각의 디스크립터는 자신만의 디스크립터 테이블에 저장되지만, 그 디스크립터들은 동일한 오픈 파일 테이블 엔트리를 공유할 수 있다.
파일 정보 구조체 : vnode 테이블
오픈 파일 테이블에서 한 단계 더 들어가면, 파일 정보 자체를 담고 있는 구조체, 보통 vnode 또는 inode가 있다. 이것은 실제 파일의 크기, 접근 권한, 타입, 소유자, 생성/수정 시간 등 모든 메타데이터를 담고 있다. 이 정보는 일반적으로 디스크에 저장되어 있다가, 파일이 열릴 때 메모리로 로딩된다.
따라서 하나의 파일을 여러 프로세스가 열면, 이들은 같은 vnode(파일 정보)와 같은 오픈 파일 엔트리를 참조하고, 자신의 디스크립터 테이블만 개별적으로 갖게 된다.
예를 들어, 다음과 같은 코드가 있다고 하자.
int fd1 = open("/home/park/a.txt", O_RDONLY);
int fd2 = open("/home/park/b.txt", O_RDONLY);
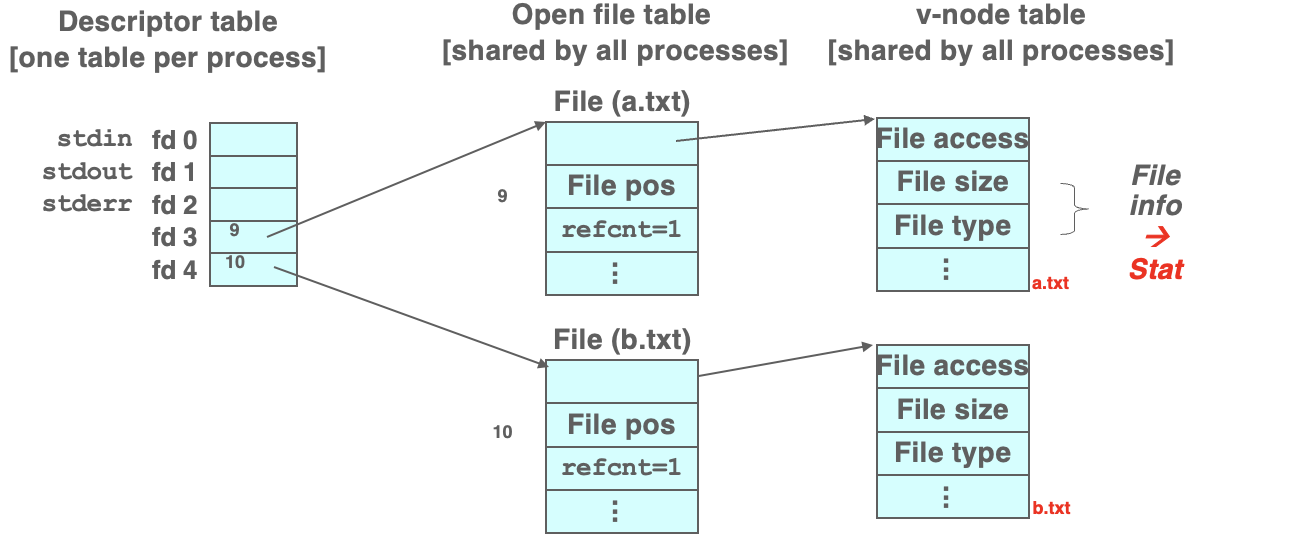
- Disk에서 a.txt, b.txt에 대한 inode 정보를 메모리에 올린다.(in memory inode를 vnode라고 함.)
- Open file table에서 빈 엔트리를 찾아(9, 10) 각각 a.txt의 vnode entry, b.txt의 vnode entry를 가리킨다.
- descriptor table에는 Open file table의 entry 번호가 저장된다. (각각의 디스크립터는 독립적인 오픈 파일 엔트리를 갖는다.)
- 위 코드에서 fd1, fd2에는 file desciptor 번호가 반환되어 저장된다.
File Metadata and Access Mechanisms
Metadata?
메타데이터(metadata)는 쉽게 말해 “파일 자체에 대한 정보”를 의미한다. 파일의 실제 내용(data)이 아니라, 파일을 정의하고 설명하는 모든 속성 정보가 이에 해당한다. 대표적으로 다음과 같은 항목들이 있다:
- 파일의 크기
- 생성, 수정, 접근 시간
- 파일 타입(일반 타입, 디렉터리, 장치 파일 등)
- 파일 소유자 및 권한
- 디바이스 번호, 블록 크기, 블록 수 등
이러한 메타 데이터는 운영체제의 커널이 관리하며, 사용자는 stat, fstat과 같은 함수로 접근할 수 있다.
stat과 fstat 함수
int stat(const char *path, struct stat *buf);
int fstat(int filedes, struct stat *buf);
- stat() 함수는 파일 경로를 기반으로 메타데이터를 가져온다.
- fstat() 함수는 이미 열린 파일 디스크립터를 통해 메타 데이터를 가져온다.
메타데이터는 struct stat 구조체로 반환되며, 이 안에는 다양한 필드들이 포함된다. 예를 들어 st_size는 파일의 크기, st_mode는 권한과 파일 종류, st_mtime은 마지막 수정 시각을 의미한다.
/* Metadata returned by the stat and fstat functions */
struct stat {
dev_t st_dev; /* device */
ino_t st_ino; /* inode */
mode_t st_mode; /* protection and file type */
nlink_t st_nlink; /* number of hard links */
uid_t st_uid; /* user ID of owner */
gid_t st_gid; /* group ID of owner */
dev_t st_rdev; /* device type (if inode device) */
off_t st_size; /* total size, in bytes */
unsigned long st_blksize; /* blocksize for filesystem I/O */
unsigned long st_blocks; /* number of blocks allocated */
time_t st_atime; /* time of last access */
time_t st_mtime; /* time of last modification */
time_t st_ctime; /* time of last change */
};
예시 코드:
void Stat(char* path, struct stat* pStat) {
if (stat(path, pStat) < 0) {
perror("stat");
exit(-1);
}
}
이런 인터페이스를 통해 사용자 프로그램은 파일의 상태를 파악하고 동작을 제어할 수 있다.
파일 오프셋(File Offset)
파일 디스크립터에는 항상 “지금 어디까지 읽었는가?”에 대한 위치 정보(offset)가 포함된다. 이는 마치 책에서 책갈피를 끼워두는 것과 비슷하다. 다음 read()나 write() 호출 시 이 위치부터 동작이 시작된다.
예를 들어, 아래 코드는 파일로부터 최대 512바이트를 읽어온다:
char buf[512];
int fd = open("file.txt", O_RDONLY);
int nbytes;
if ((nbytes = read(fd, buf, sizeof(buf))) < 0) {
perror("read");
exit(1);
}
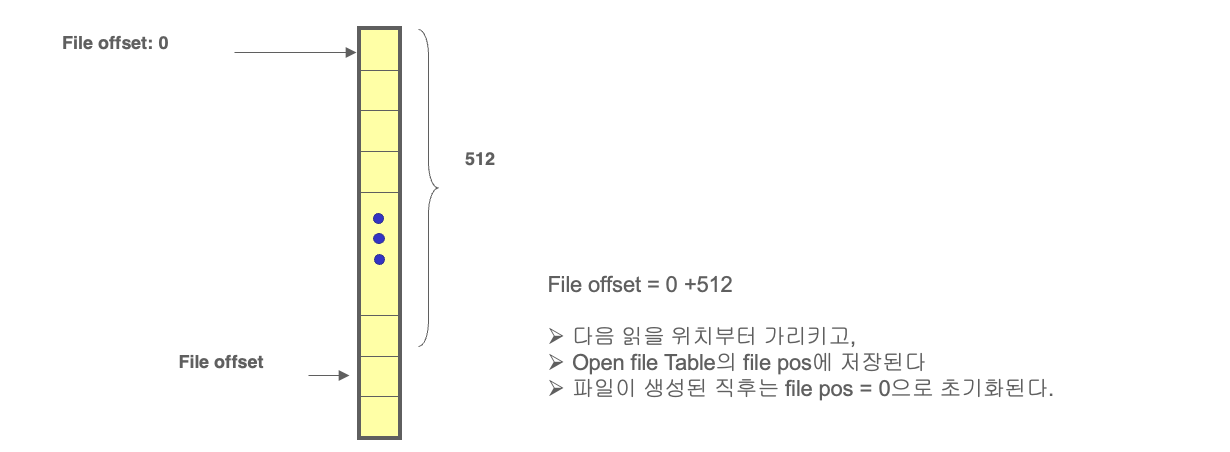
이 경우 read()가 성공하면, 파일 오프셋은 자동으로 512바이트만큼 증가하며 다음 읽기 동작은 그 이후부터 시작된다. 이 메커니즘 덕분에 연속적인 파일 접근이 가능하다.
UNIX File Sturcture and Logical Layers
UNIX 계열 시스템은 계층화된 파일 시스템 구조를 갖고 있다. 이 구조는 논리적 수준에서 물리적 저장장치까지 단계를 나누어 파일 시스템을 효율적으로 관리한다:
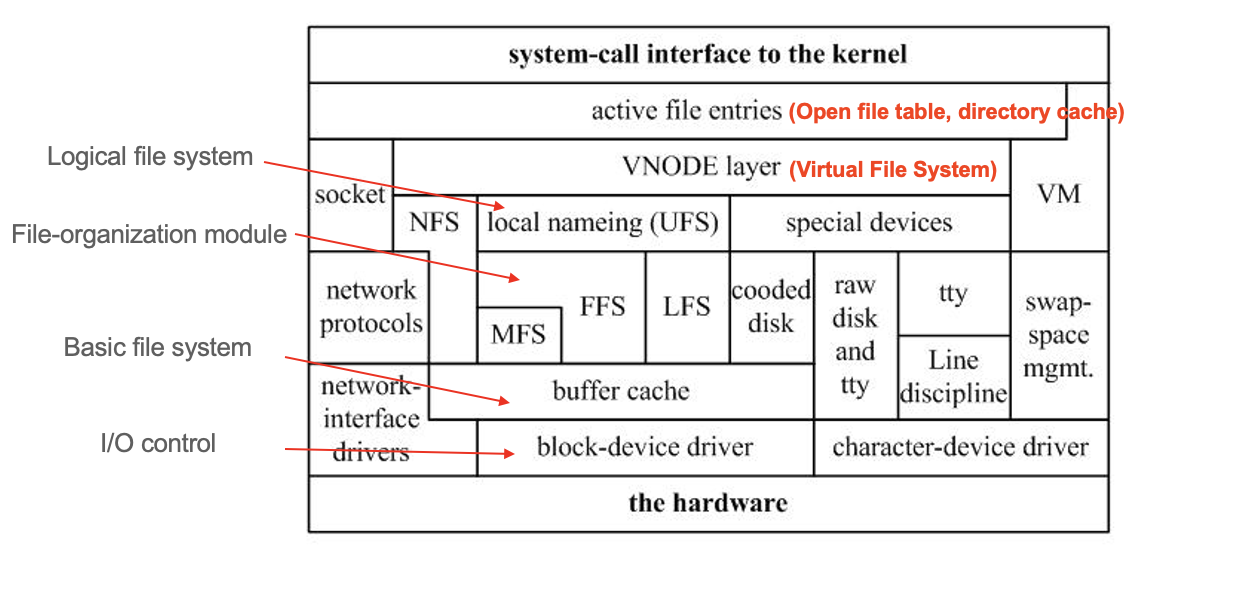
- Logical File System : 파일 이름, 디렉토리, 권한, 접근 제어 등 사용자 관점의 기능을 제공한다.
- File Organization Module : 블록 매핑, 인덱스 블록 관리, 디렉토리 엔트리 해석 등을 담당한다.
- Basic File System : 실제 데이터가 저장된 블록을 읽고 쓴다.
- I/O Control Layer : 디바이스 드라이버를 통해 하드웨어와 통신하며, 디스크에 물리적으로 접근한다.
이 구조는 모듈화를 통해 다양한 파일 시스템 타입을 지원하고, 유지보수나 확장을 유리하게 만든다.
Virtual File Systems(VFS)
현대 운영체제는 하나의 파일 시스템만을 다루지 않는다. 동일한 시스템 내에 ext2, FAT32, NTFS, NFS 같은 서로 다른 파일 시스템이 공존할 수 있으며, 사용자들은 이러한 차이를 인식하지 못한 채 동일한 방식으로 파일에 접근할 수 있다. 이를 가능하게 하는 핵심 구조가 바로 가상 파일 시스템(Virtual File System, VFS)이다.
가상 파일 시스템의 필요성
운영체제가 다양한 파일 시스템을 동시에 지원하려면, 아래와 같은 조건을 만족해야 한다.
- 다양한 파일 시스템 종류의 통합 : 서로 다른 디스크 파티션에 ext2, FAT, NFS 등 서로 다른 파일 시스템이 탑재되어 있어도 사용자에게는 단일한 파일 계층으로 보이도록 해야 한다.
- 일관된 시스템 콜 인터페이스 : 사용자는 open(), read(), write() 등의 시스템콜을 통해 어떤 파일 시스템이든 동일한 방식으로 접근할 수 있어야 한다.
- 확장성과 모듈성 : 새로운 파일 시스템이 등장했을 때, 커널 전체를 수정하지 않고도 쉽게 새로운 파일 시스템을 추가할 수 있어야 한다.
가상 파일 시스템의 구조
VFS는 위 요구사항을 만족시키기 위해 파일 시스템의 공통 인터페이스를 정의하고, 각 파일 시스템이 이를 구현하도록 강제한다. 이 구조에서 핵심 역할을 수행하는 것이 바로 vnode (virtual node)이다.
- vnode는 파일의 공통적인 표현을 추상화한 구조체이다.
- 각 파일 시스템은 vnode 구조를 자체 포맷에 맞게 구현하고, vnodeops라는 함수 집합을 통해 동작을 연결한다.
VFS 계층에서 write(fd, buf, len) 같은 시스템 콜이 호출되면, 내부적으로는 VOP_WRITE()와 같은 추상화된 함수가 호출되고, 이 함수는 등록된 파일 시스템의 fat::write()나 ntfs::write() 같은 실제 구현 함수로 연결된다.
vnodeops - 파일 시스템별 함수 구현 : VFS 계층에서 write(fd, buf, len) 같은 시스템 콜이 호출되면, 내부적으로는 VOP_WRITE()와 같은 추상화된 함수가 호출되고, 이 함수는 등록된 파일 시스템의 fat::write()나 ntfs::write() 같은 실제 구현 함수로 연결된다.

이처럼 각 파일 시스템은 자신의 정책과 구조에 따라 vnode 연산을 구현하되, VFS 인터페이스는 동일하게 유지된다. 이는 모듈화된 커널 아키텍처의 대표적인 예다.
VFS가 하는 두가지 주요 역할
-
파일 시스템 독립적인 연산과 구현을 분리 : 사용자가 read()를 호출하면, VFS는 어떤 파일 시스템이든 관계없이 공통된 처리 경로로 분기한 후, 해당 파일 시스템의 실제 처리 함수로 연결해준다.
-
모든 파일을 고유하게 표현 : 시스템 내의 모든 파일은 vnode를 통해 고유하게 표현된다. 이는 네트워크 파일 시스템(NFS)과 같은 외부 파일 시스템에서도 통일된 구조로 관리될 수 있음을 의미한다.
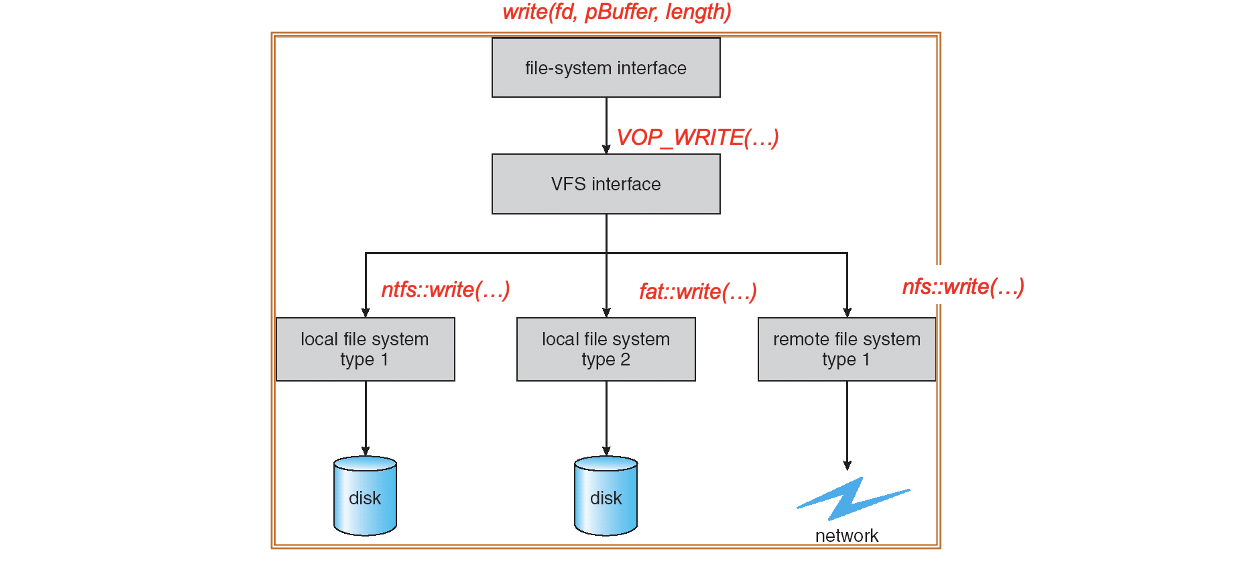
Directory - 파일 시스템의 조직 구조
운영체제의 파일 시스템은 수많은 파일을 효율적으로 저장하고 찾을 수 있어야 한다. 이를 위해 계층적 구조를 사용하는데, 이 구조의 핵심 구성요소가 바로 디렉터리(directory)다.
디렉터리(Directory)?
디렉터리는 파일 이름과 그에 대응하는 정보를 저장하는 특수한 파일이다. 디렉터리 안에는 여러 개의 디렉터리 엔트리(directory entry)가 존재하며, 각각은 하나의 파일(또는 하위 디렉터리)을 참조한다.
- 디렉터리는 단순한 문자열 리스트가 아니라, 각 항목마다 파일 이름, 파일 타입, inode 번호(또는 포인터)를 포함한다.
- 디렉터리는 일반 파일처럼 보이지만, 구조적으로는 파일들을 관리하는 컨테이너 역할을 한다.
디럭터리 열기
디렉터리를 열 때는 opendir() 함수를 사용한다. 이는 내부적으로 파일을 여는 것과 비슷하지만, 반환되는 포인터는 디렉터리 전용이다.
DIR* dirp;
if ((dirp = opendir("/home/park")) == NULL) {
perror("opendir");
exit(1);
}
- drip는 디렉터리 포인터이며, 이후 readdir()에서 사용된다.
- 디렉터리를 열면, 시스템은 해당 디렉터리의 첫 번째 항목을 가리키는 포인터를 준비한다.
디렉터리 엔트리 읽기
디렉터리 내의 항목을 하나씩 읽기 위해 readdir() 함수를 사용한다.
struct dirent* dentry;
while ((dentry = readdir(dirp)) != NULL) {
printf("name: %s, type: %d\n", dentry->d_name, dentry->d_type);
}

- struct dirent 구조체는 각 엔트리의 정보(파일 이름, 타입, inode 번호 등)을 포함한다.
- 파일 타입은 일반 파일, 디렉터리, 링크 등의 구분을 나타낸다.
- readdir()은 포인터를 다음 엔트리로 자동 이동시키며, 디렉터리 끝에 도달하면 NULL을 반환한다.
디렉터리 닫기
디렉터리를 모두 읽은 후에는 반드시 닫아야 한다. 이는 closedir() 함수로 수행한다.
if (closedir(dirp) < 0) {
perror("closedir");
exit(1);
}
- 닫기 작업은 파일 디스크립터처럼 자원을 반환하고 메모리를 해제하는 역할을 한다.
디렉터리 생성
로운 디렉터리는 mkdir() 함수를 통해 생성할 수 있다
if (mkdir("/home/park/programs", S_IRUSR | S_IWUSR) < 0) {
perror("mkdir");
exit(1);
}
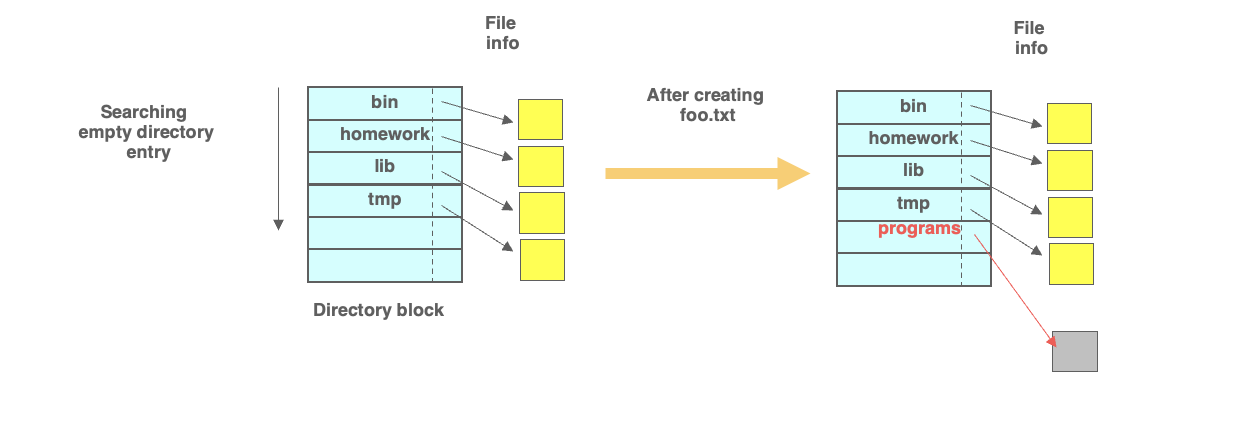
- S_IRUSR와 S_IWUSR는 사용자 읽기/쓰기 권한을 의미한다.
- 디렉터리를 만들기 위해서는 해당 경로의 상위 디렉터리가 존재하고, 쓰기 권한이 있어야 한다.
디렉터리 구현 방식 - Directory Implementation
디렉터리는 운영체제에 따라 다양한 방식으로 구현될 수 있지만, 가장 기본적인 방법은 선형 리스트(linear list) 방식이다.
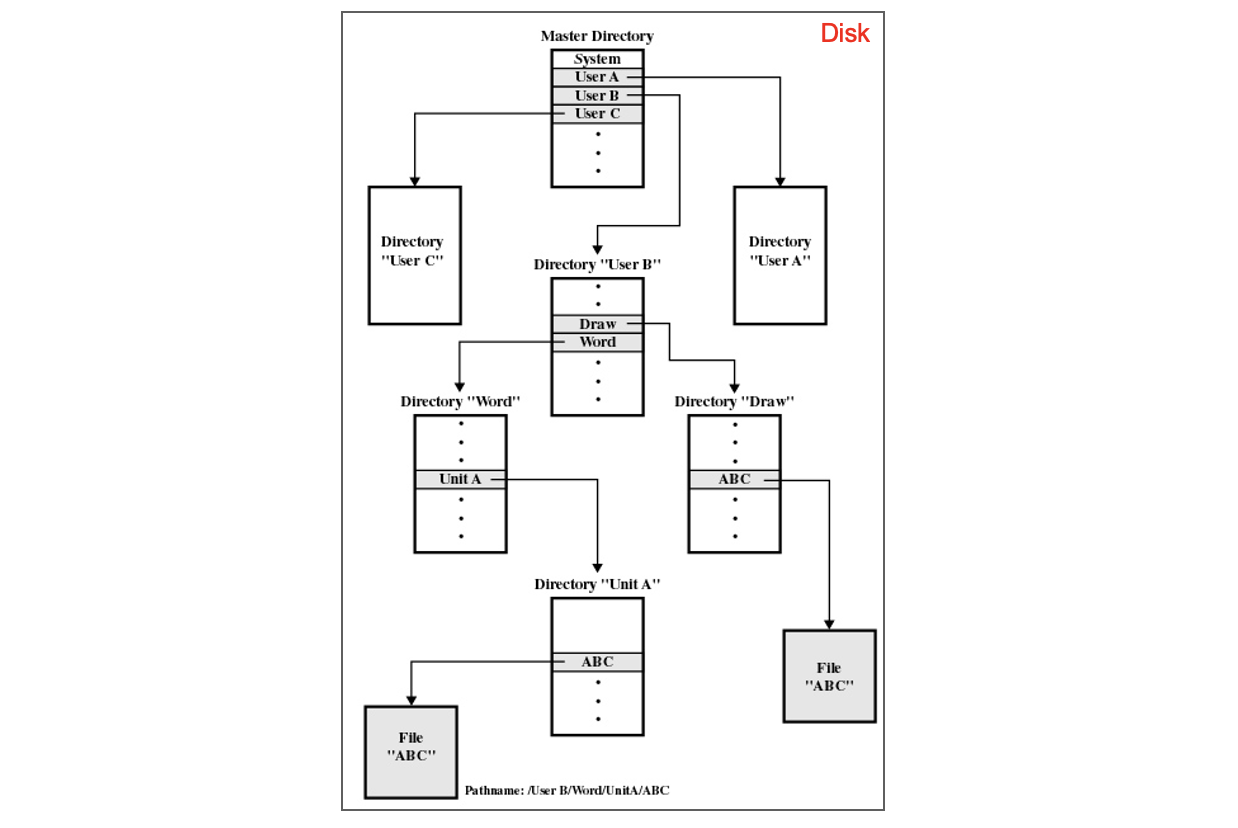
선형 리스트 방식
- 디렉터리는 여러 개의 디렉터리 블록으로 구성된다.
- 각 블록은 파일 이름과 해당 파일을 가리키는 포인터 또는 inode 번호를 포함한다.
- 새로운 파일을 추가할 때는 리스트 끝에 항목을 추가한다.
- 삭제할 때는 해당 엔트리를 비활성화(예: 삭제 표시 또는 NULL 포인터)한다.
이 방식의 장점은 단순성이다. 구현이 쉽고, 파일 시스템이 작을 경우에는 효율적으로 동작한다. 하지만 단점도 분명하다.
단점 : 검색 성능의 저하 : 파일을 열거나 삭제하기 위해서는 리스트의 처음부터 끝까지 순차 탐색(linear search)을 수행해야 하므로, 디렉터리 엔트리가 많아질수록 성능이 급격히 떨어진다. 예를 들어, 1,000개의 파일이 있는 디렉터리에서 마지막 파일을 찾으려면 1,000번 비교해야 한다.
디렉터리 캐시 - Directory Cache
이러한 성능 저하 문제를 보완하기 위해, 대부분의 운영체제는 디렉터리 캐시(directory cache)를 사용한다.
- 디렉터리 캐시는 최근 접근한 디렉터리 엔트리를 메모리에 저장해두는 구조다.
- 디스크를 매번 탐색하지 않고, 메모리에서 빠르게 탐색할 수 있어 성능이 향상된다.
- open()이나 mkdir() 같은 함수의 성능이 크게 향상되는 효과를 낳는다.
Allocation Methods
운영체제는 파일을 저장할 때, 디스크의 어느 블록에 어떤 순서로 저장할지를 결정해야 한다. 이때 사용하는 전략이 바로 할당 방식(Allocation Method)이다. 할당 방식은 파일의 성능, 공간 낭비 여부, 접근 속도, 확장성에 직접적인 영향을 미친다.
대표적인 할당 방식은 다음 세 가지다:
- 연속 할당(Contiguous Allocation)
- 연결 할당(Linked Allocation)
- 인덱스 할당(Indexed Allocation)
Logical Block vs Physical Block
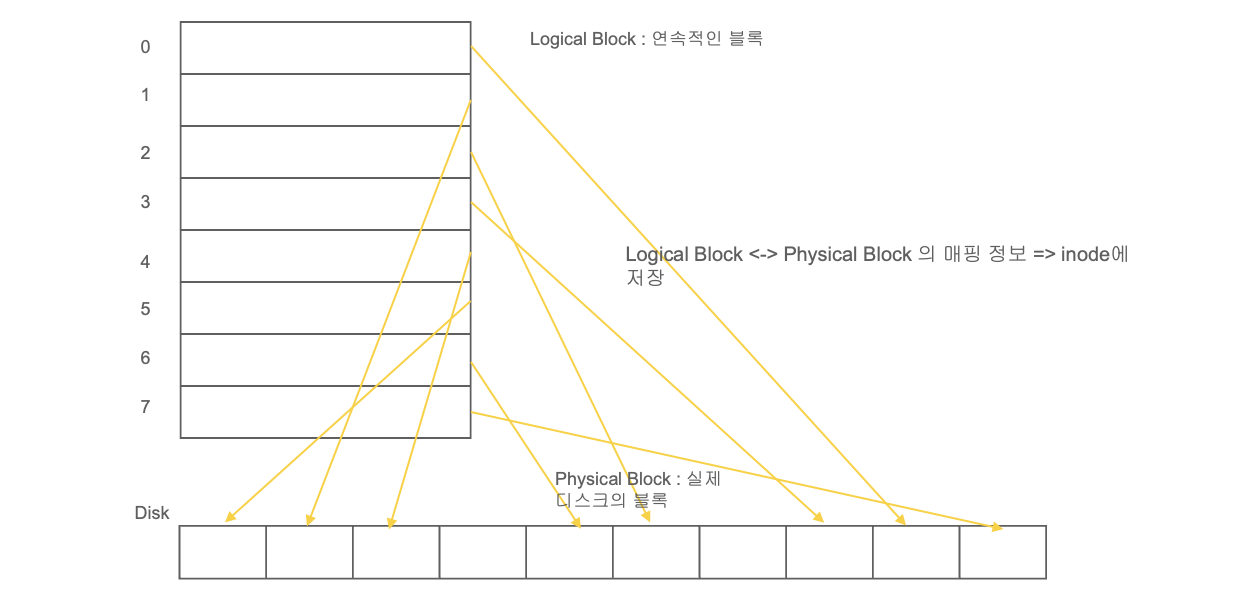
파일 시스템이 디스크 위에 데이터를 저장할 때, 사용자와 운영체제 사이에서는 추상적인 논리 단위로 데이터를 다루는 반면, 실제 디스크는 물리적인 단위로 데이터를 저장한다. 이 두 관점의 차이를 구분하는 것이 Logical Block(논리 블록)과 Physical Block(물리 블록)이다.
Physical Block(물리 블록) : 물리 블록은 디스크 하드웨어가 직접 다루는 최소 단위이다. 디스크는 원형 플래터에 데이터를 저장하며, 이 플래터는 트랙(track)과 섹터(sector)로 나뉜다. 일반적으로 하나의 섹터는 512바이트 또는 최근에는 4096바이트(4KB) 크기를 가진다.
즉, 물리 블록은 다음과 같은 특성을 갖는다:
- 디스크 컨트롤러가 인식하고 접근하는 실제 저장 단위
- 1:1로 디스크 상의 섹터 또는 여러 섹터의 집합일 수 있다.
- 고정된 크기(전통적으로는 512B, 요즘은 4KB)
Logical Block(논리 블록) : 논리 블록은 파일 시스템이나 운영체제가 데이터를 다루는 단위다. 실제 디스크 구조를 알 필요 없이, 사용자나 프로그램이 데이터를 추상적으로 이해할 수 있도록 만든 가상의 블록이다.
- 파일 시스템이 내부적으로 사용하는 데이터 단위
- 논리 블록 하나가 실제 여러 물리 블록과 매핑될 수 있다.
- 파일 시스템마다 논리 블록 크기는 다를 수 있다.(보통 1KB, 2KB, 4KB 등)
예를 들어, 어떤 파일 시스템에서 논리 블록 크기를 4KB로 설정했다고 가정해보자. 디스크가 512바이트 단위로 데이터를 저장한다면, 하나의 논리 블록은 8개의 물리 블록에 해당하게 된다.
논리 블록, 물리 블록 매핑 : 운영체제는 논리 블록 번호를 가지고 실제 물리 블록 주소를 계산해야 한다. 이를 블록 매핑(block mapping)이라고 하며, 인덱스 블록, FAT, ext2 등 다양한 방식으로 매핑이 관리된다.
- 사용자 : “논리 블록 5번 읽어줘!”
- 파일 시스템 : “논리 블록 5번은 물리 디스크의 2210번 블록이야”
- 디스크 컨트롤러 : 2210번 블록을 읽어서 메모리로 전달
이렇게 추상화 계층이 나뉘어 있기 때문에, 운영체제는 하드웨어의 물리적 구조를 몰라도 데이터를 효율적으로 다룰 수 있다.
연속 할당(Contiguous Allocation)
하나의 파일을 디스크의 연속된 블록들에 저장하는 방식이다. 시작 블록 주소와 파일의 길이만 기억하면 파일 전체를 추적할 수 있다.

예를 들어, 시작 위치가 b, 파일이 n개의 블록을 차지하면, 이 파일은 블록 b부터 b + n - 1까지 차지한다.
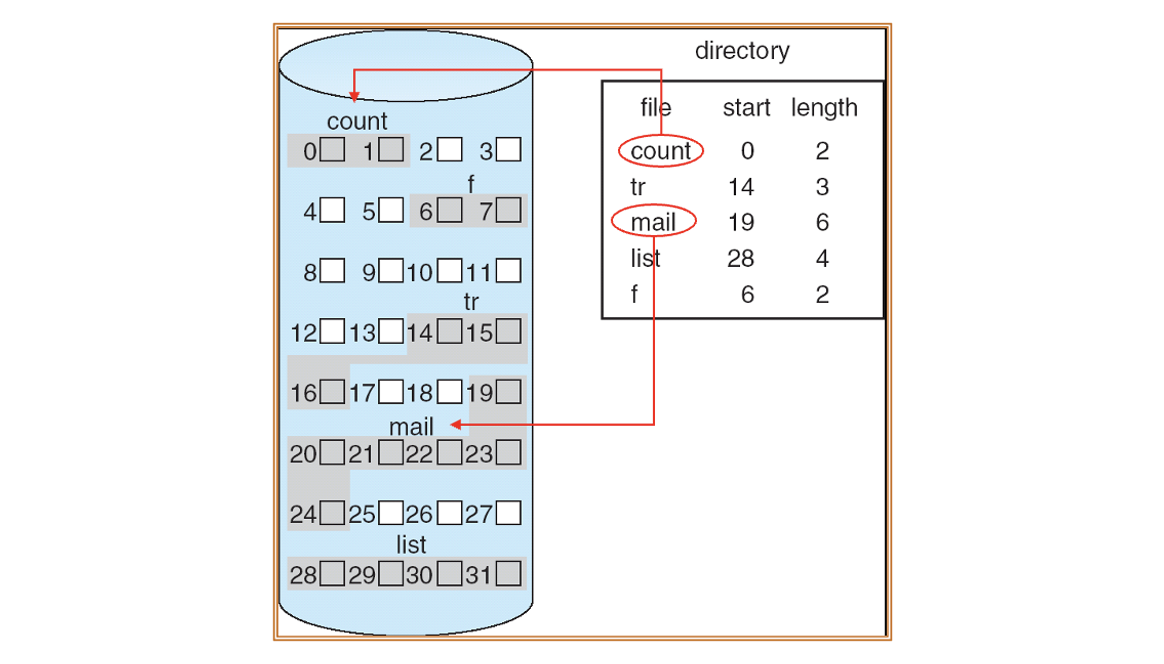
장점 :
- 빠른 순차 접근 : 블록이 연속되어 있으므로 읽기/쓰기가 매우 빠르다.
- 파일의 시작 위치만 알면 전체 접근 가능
단점 :
- 외부 단편화(External Fragmentation) : 여러 파일의 생성과 삭제로 인해 빈 공간이 조각나게 되어 큰 파일을 연속된 공간에 저장하기 어렵다.
- 파일 크기 예측의 어려움 : 초기 할당 시 얼마나 공간을 잡아야 할지 예측해야 하는데, 부족하면 확장이 어렵다.
연결 할당(Linked Allocation)
파일을 연속되지 않은 블록들에 저장하되, 각 블록에 다음 블록을 가리키는 포인터를 포함시킨다. 파일은 연결 리스트 구조로 구성된다.
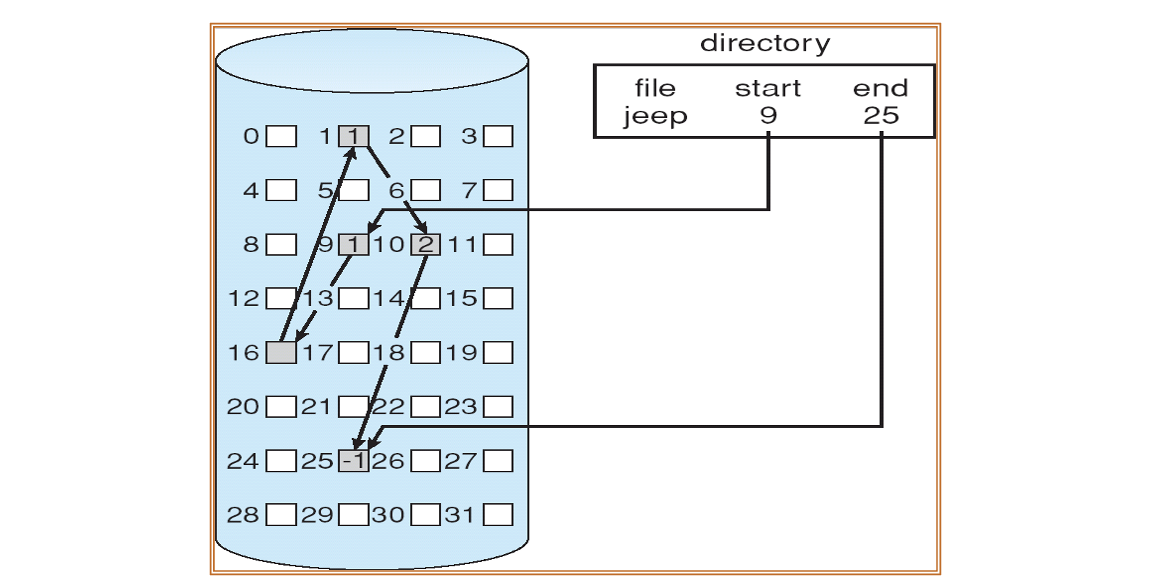
예시 :
- 첫 블록에는 데이터 + 다음 블록 주소가 저장됨
- 마지막 블록의 포인터는 NULL
장점 :
- 외부 단편화 없음 : 아무 위치에나 블록을 배치할 수 있어 공간 활용에 유리하다.
- 파일 확장이 쉽다.
단점 :
- 랜덤 접근이 비효율적 : i번째 블록을 접근하려면 첫 블록부터 차례로 따라가야 한다.
- 포인터 오버헤드 : 각 블록에 포인터 저장 공간이 필요하다.(예: 512B 블록에 4B 포인터 -> 약 0.78% 낭비)
- 포인터 오류 위험성 : 블록 손상 시 전체 파일을 못 읽을 수 있다.
연결 할당 변형 : FAT(File Allocation Table)
포인터를 블록 내부가 아닌, 별도의 테이블(FAT)에 저장하는 방식이다. 디스크의 처음 부분에 FAT가 존재하며, 각 인덱스는 해당 블록의 다음 블록을 가리킨다.
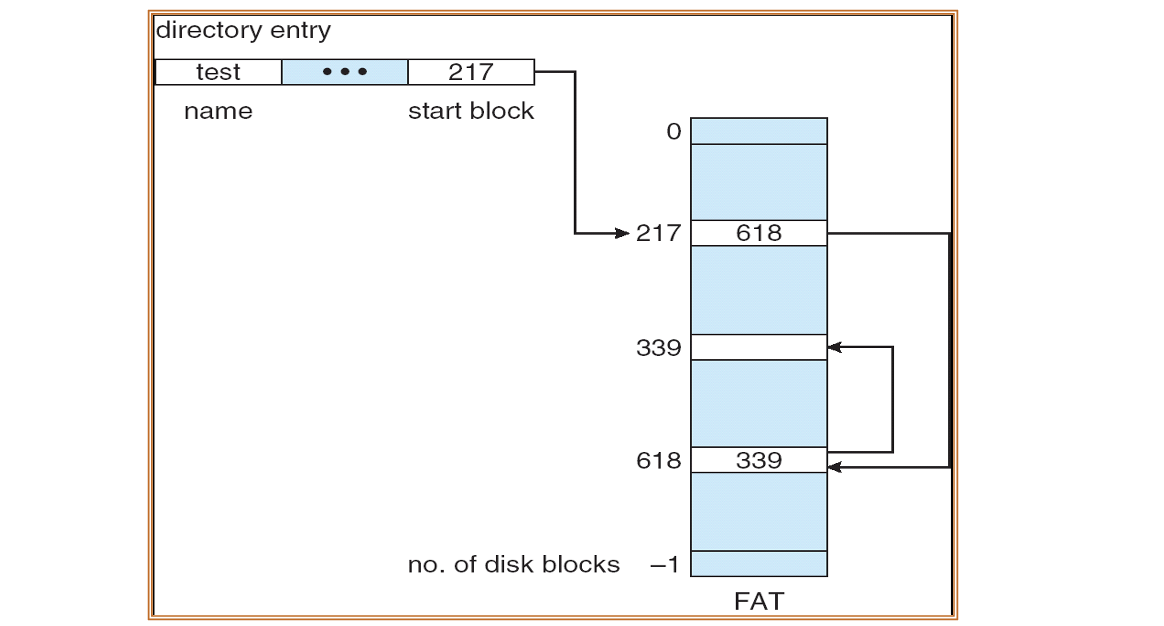
특징
- 파일 시스템이 포인터를 한 곳에서 관리하므로, 블록 자체는 순수 데이터 저장 용도로만 사용된다.
- MS-DOS, USB, 메모리 카드 등에서 널리 사용된다.
장점
- 블록 손상에도 데이터 연쇄가 유지된다.
- 포인터 정보가 캐시에 들어가므로 검색이 빠르다.
단점
- FAT 테이블이 커지면, 캐시 부하가 커지고 디스크 접근이 많아질 수 있다.
인덱스 할당(Indexed Allocation)
파일의 모든 블록 주소를 모은 인덱스 블록을 따로 두고, 그 블록에 각 데이터 블록의 위치를 저장한다.
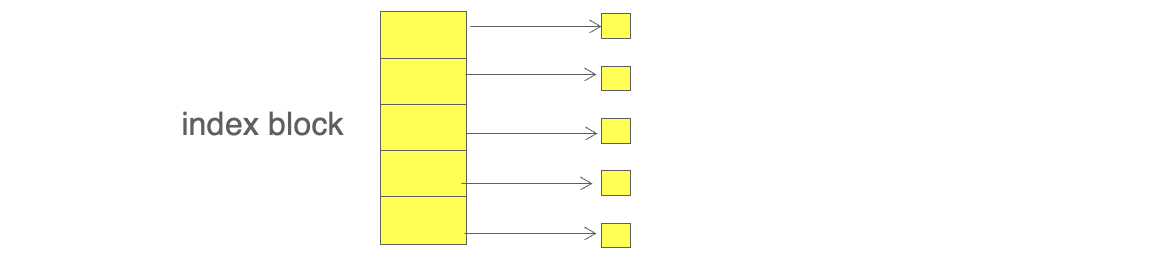
장점
- 랜덤 접근에 유리함 : 인덱스만 보면 바로 원하는 블록으로 이동 가능
- 외부 단편화 없음
단점
- 인덱스 블록의 크기 한계 : 큰 파일일수록 인덱스 블록 하나로는 부족하다.
- 이를 해결하기 위해 여러 레벨의 인덱스를 구성해야 한다.
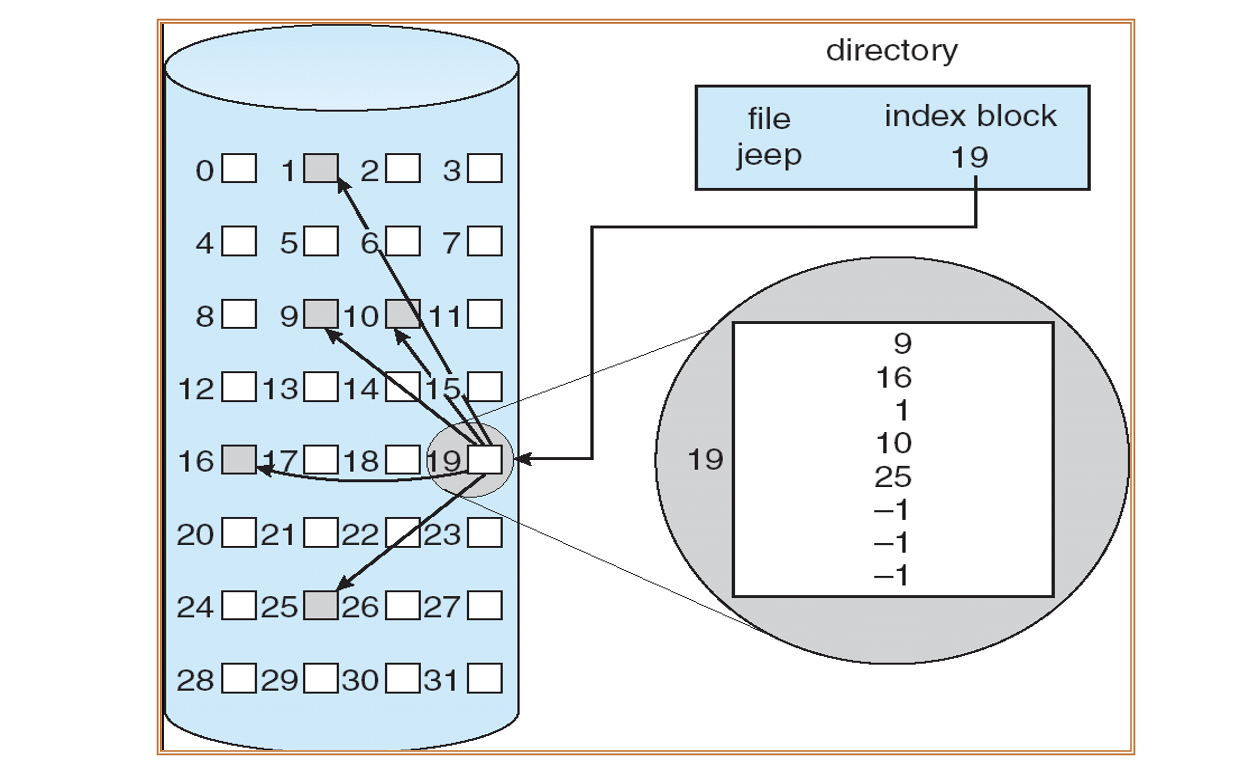
인덱스 할당(Indexed Allocation) : 확장 전략과 구조 최적화
인덱스 할당의 단점 : 포인터 오버헤드 : 인덱스 할당은 파일의 모든 데이터 블록 주소를 하나의 인덱스 블록(index block)에 저장하는 방식이다. 이는 랜덤 접근에 유리한 장점이 있지만, 작은 파일에는 공간 낭비(wasted space)가 발생할 수 있다.
예를 들어, 어떤 파일이 1~2개의 데이터 블록만 필요하더라도, 전체 인덱스 블록 하나를 무조건 할당해야 한다. 이로 인해 수백 또는 수천 개의 포인터 공간이 낭비되는 것이다. 즉, 인덱스 할당은 작은 파일에 비효율적일 수 있다는 구조적 단점을 갖는다.
인덱스 블록 관리 기법 : 이 문제를 해결하기 위해 운영체제는 다양한 인덱스 블록 확장 기법을 도입했다. 대표적인 세 가지 기법은 다음과 같다:
- Linked Scheme(연결 방식)
- 기본 구조 : 하나의 인덱스 블록만으로 부족할 경우, 여러 인덱스 블록을 연결 리스트처럼 연결한다.
- 적용 상황 : 큰 파일을 저장할 때 유용하며, 각 인덱스 블록이 새로운 블록을 가리키는 포인터를 포함한다.
- 장점 : 단순한 구조로 구현이 쉽다.
- 단점 : 블록을 순차적으로 탐색해야 하므로, 접근 속도가 느리다. 랜덤 접근에는 부적합
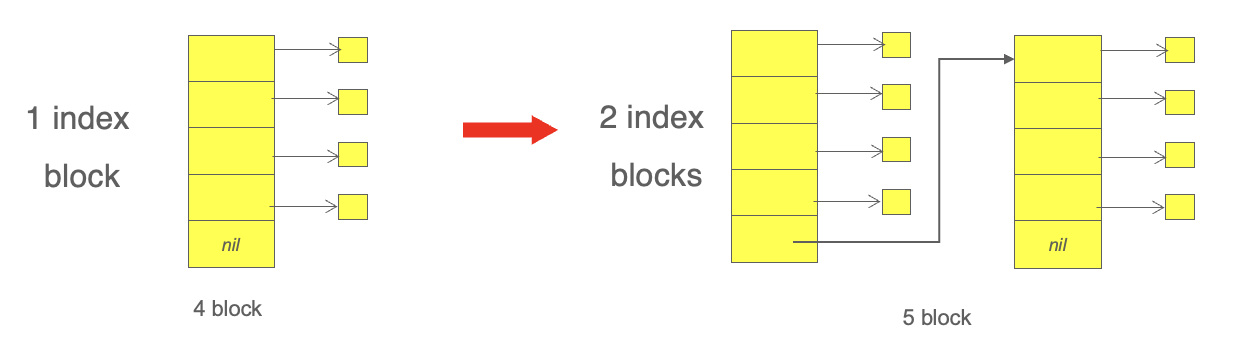
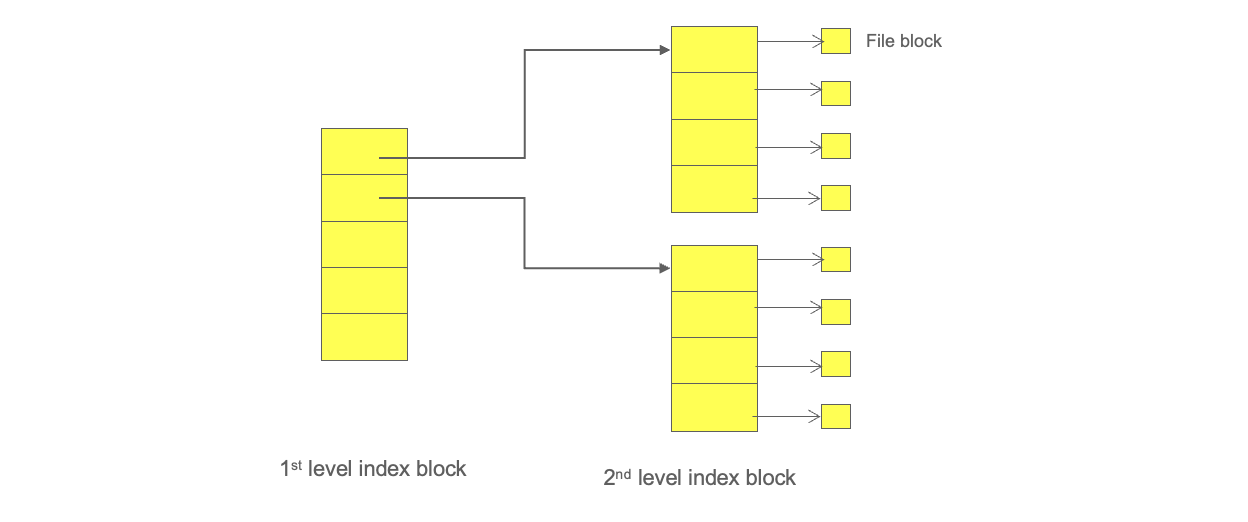
- Multilevel Index(다단계 인덱스 방식)
- 기본 구조 : 1단계 인덱스 블록이 2단계 인덱스 블록들을 가리키고, 2단계 블록이 실제 데이터 블록들을 가리킨다.
- 적용 상황 : 매우 큰 파일을 효과적으로 다루기 위해 사용됨.
- 장점 : 계층적으로 확장 가능하므로 파일 크기의 제약이 적음.
- 단점 : 파일 끝부분에 접근할수록 다단계 탐색으로 인한 오버헤드가 발생.
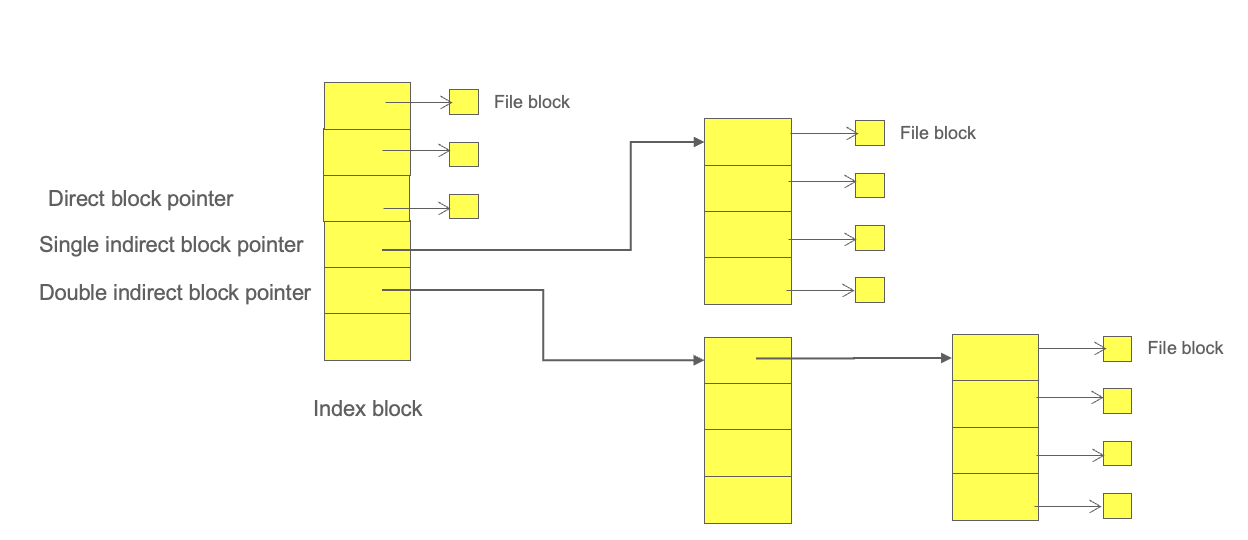
- Combined Scheme(결합 방식, UNIX inode 구조)
- 기본 구조 : 하나의 인덱스 블록 안에 다음과 같은 포인터들을 결합하여 사용
- 12개의 직접 블록 포인터 (direct block pointers)
- 1개의 단일 간접 포인터 (single indirect)
- 1개의 이중 간접 포인터 (double indirect)
- 1개의 삼중 간접 포인터 (triple indirect)
- 동작 방식
- 작은 파일은 직접 포인터만으로 처리하고,
- 파일 크기가 커질수록 간접 블록을 점진적으로 사용함.
- 장점
- 작은 파일은 빠르게 접근이 가능하고, 큰 파일도 점진적 확장으로 효율적으로 다룰 수 있다.
- 기본 구조 : 하나의 인덱스 블록 안에 다음과 같은 포인터들을 결합하여 사용
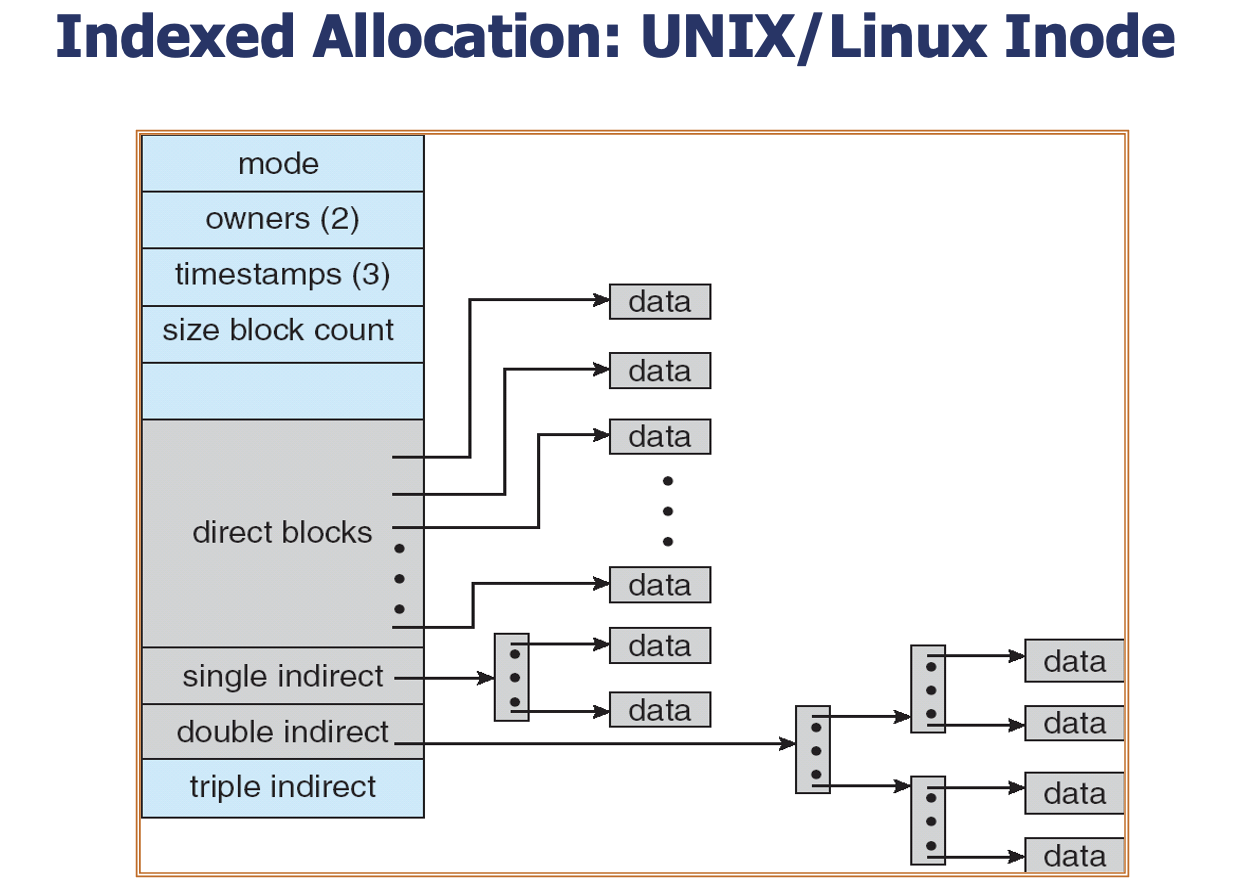
소규모 파일 시스템의 내부 구조 - Internal Structure of a Small File System
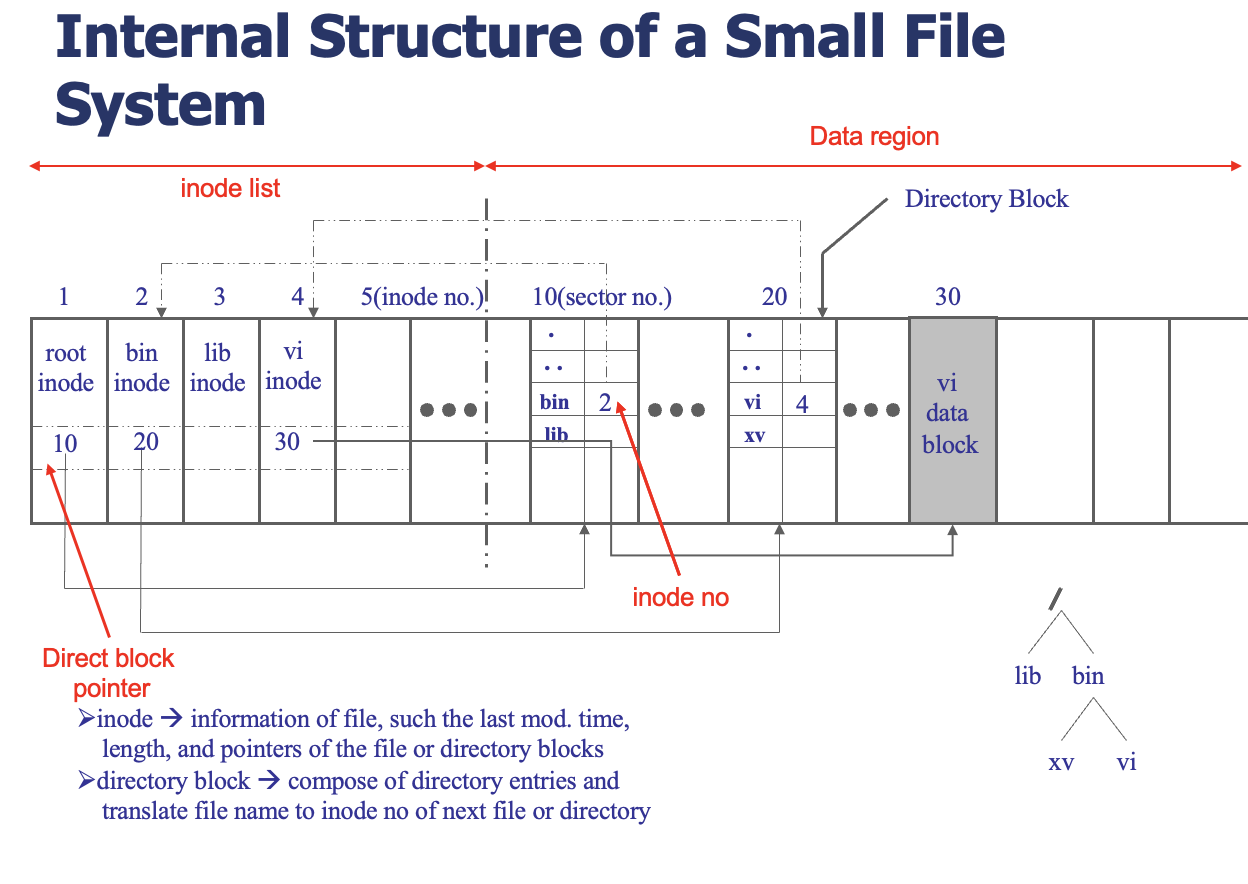
Free Space Management : 디스크 공간 재사용
파일 시스템은 사용자가 파일을 삭제하면, 그 공간을 새로운 파일 저장을 위해 재사용할 수 있어야 한다. 이를 위한 핵심 요소가 Free Space List (빈 공간 목록)이다.
동작 방식 :
- 파일을 삭제할 때: 해당 블록 번호가 free space list에 추가됨.
- 파일을 생성할 때: free space list에서 적당한 공간을 찾아 할당함.
빈 공간 목록은 단순한 리스트로 유지할 수도 있고, 더 효율적인 방식으로는 비트맵(bit map)을 사용한다.
비트맵 방식의 Free Space Management
디스크의 각 블록에 대해 1비트씩 사용하여 해당 블록의 상태(사용 중/비어있음)를 나타낸다. bit[i] = 0이면 i번 블록이 비어있음, 1이면 사용중

장점 :
- 공간 절약 : 1비트로 하나의 블록 상태 표현 가능
- 빠른 탐색 : CPU의 비트 연산 명령을 이용해 빠르게 찾을 수 있음
- 캐시 활용 효율 : 자주 사용하는 비트맵은 메모리에 올려 두고 빠르게 접근 가능
예시 : 디스크 블록 번호 중 2, 3, 4, 5, 8, 9, 10, 12, 13, 17, 25~27번이 사용 중이면
비트맵: 0011110011111100011000000111100000
Buffer Cache - 디스크 접근 최소화를 위한 캐시 메커니즘
디스크는 느리다. 파일을 읽거나 쓸 때마다 디스크를 직접 접근하면 성능은 크게 떨어진다. 이를 해결하기 위해 운영체제는 자주 사용되는 디스크 블록을 메모리에 유지하는데, 이를 버퍼 캐시(buffer cache)라고 한다.
버퍼 캐시란?
- 메모리(RAM)에 디스크 블록의 사본을 저장해 두는 캐시
- 파일 읽기 시, 먼저 버퍼 캐시르르 확인하고, 없을 경우에만 디스크 접근
- 파일 쓰기 시, 디스크에 바로 쓰지 않고 버퍼 캐시에 먼저 저장
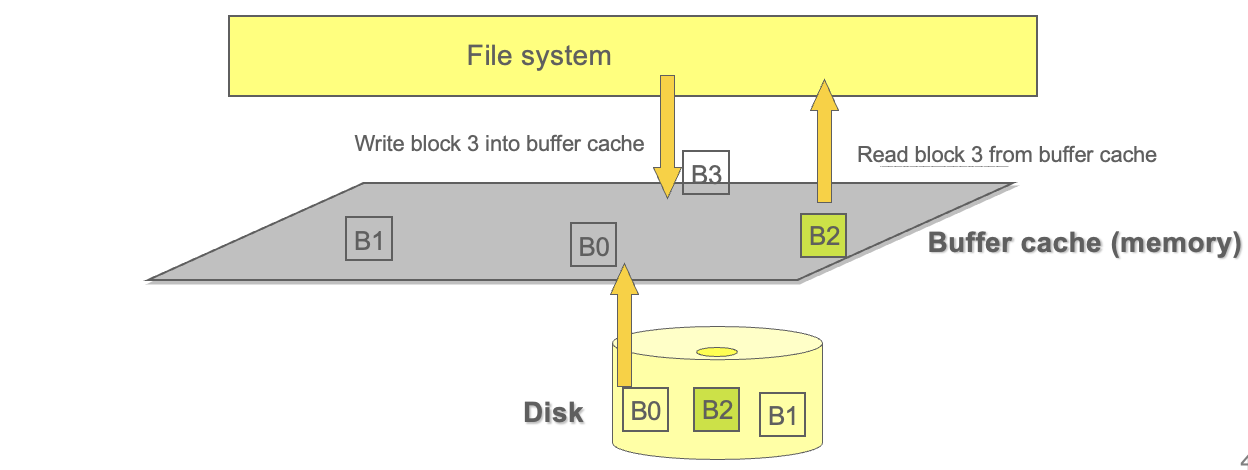
캐시의 핵심 효과 : 지역성 활용
파일 접근에는 시간적 지역성(Temporal Locality)이 있다. 즉, 한 번 접근한 파일은 곧 다시 접근될 가능성이 크다.
이러한 특성 때문에 캐시에 저장해두면 성능이 크게 향상된다. 예를 들어:
- 어떤 프로그램이 config.txt 파일을 5초 간격으로 읽는다면, 캐시에 저장된 내용을 읽는 것이 디스크를 매번 접근하는 것보다 훨씬 빠르다.
시스템 구조 내에서의 역할
[Application Layer]
↓
[File System Interface]
↓
[Buffer Cache]
↓
[Disk Device Driver] → 디스크 하드웨어
또한, vnode 계층, 파일 시스템 별 드라이버 (UFS, NFS 등), 그리고 페이지 캐시/네트워크 캐시와도 상호작용한다. 이처럼 버퍼 캐시는 단순한 임시 저장 공간이 아니라, 운영체제 I/O 전체 흐름에서 중심적인 최적화 장치다.